ANOVA
2019-05-09
Last updated: 2019-05-17
Checks: 6 0
Knit directory: mcfa-fit/
This reproducible R Markdown analysis was created with workflowr (version 1.3.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190507) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: .RDataTmp
Unstaged changes:
Modified: analysis/about.Rmd
Modified: analysis/fit_boxplots.Rmd
Modified: analysis/index.Rmd
Modified: analysis/roc_analyses.Rmd
Deleted: docs/.nojekyll
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | fb03a30 | noah-padgett | 2019-05-09 | Build site. |
| Rmd | 54bff7b | noah-padgett | 2019-05-09 | anova-results reran |
Purpose of this file:
- Conduct ANOVA’s to get effect size study design
Packages and Set-Up
## Chunk iptions
knitr::opts_chunk$set(out.width = "225%")
# setwd('C:/Users/noahp/Dropbox/MCFA Thesis/Code Results')
## Packages General Packages
library(tidyverse)-- Attaching packages ---------------------------------------------- tidyverse 1.2.1 --v ggplot2 3.1.0 v purrr 0.2.5
v tibble 2.0.1 v dplyr 0.8.0.1
v tidyr 0.8.2 v stringr 1.3.1
v readr 1.3.1 v forcats 0.3.0 Warning: package 'dplyr' was built under R version 3.5.3-- Conflicts ------------------------------------------------- tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()library(car)Loading required package: carData
Attaching package: 'car'The following object is masked from 'package:dplyr':
recodeThe following object is masked from 'package:purrr':
somelibrary(psych)
Attaching package: 'psych'The following object is masked from 'package:car':
logitThe following objects are masked from 'package:ggplot2':
%+%, alpha# Formatting and Tables
library(kableExtra)
Attaching package: 'kableExtra'The following object is masked from 'package:dplyr':
group_rowslibrary(xtable)
# For plotting
library(ggplot2)
theme_set(theme_bw())
# Data manipulating
library(dplyr)
## One global parameter for printing figures
save.fig <- F
## Load up the functions needed for ANOVA and Assumption checking
source("code/r_functions.R")Data Management
sim_results <- as_tibble(read.table("data/compiled_fit_results.txt", header = T,
sep = "\t"))
## Next, turn condition into a factor for plotting
sim_results$Condition <- as.factor(sim_results$Condition)
## Next, since TLI is non-normed, any value greater than 1 needs to be
## rescaled to 1.
sim_results$TLI <- ifelse(sim_results$TLI > 1, 1, sim_results$TLI)
sim_results$TLI <- ifelse(sim_results$TLI < 0, 0, sim_results$TLI)
## Next, summarize the results of the chi-square test of model fit. This is
## done simply by comparing the p-value to alpha (0.05) and indicating
## whether the model was flagged as fitting or not. Note: if p < 0.05 then
## this variable is flagged as 0, and 1 otherwise
sim_results$Chi2_pvalue_decision <- ifelse(sim_results$chisqu_pvalue > 0.05,
1, 0)
# 0 = rejected that these data fit this model 1 = failed to reject that
# these data fit this model
## Need to make codes for the ROC analyses outcomes first, C vs. M1,M2,M12 -
## Perfect specification
sim_results$C <- ifelse(sim_results$Model == "C", 1, 0)
# second, C|M2 vs. M1|M12- correct level 1 model
sim_results$C_Level_1 <- ifelse(sim_results$Model == "C" | sim_results$Model ==
"M2", 1, 0)
# third, C|M1 vs. M2|M12- correct level 2 model
sim_results$C_Level_2 <- ifelse(sim_results$Model == "C" | sim_results$Model ==
"M1", 1, 0)Adding Labels to Conditions
Currently, each condition is kind of like a hidden id that we don’t know what the actual factor is. So, first thing isto create meaningful labels for us to use. Remember, the 72 conditions for the this study were
- Level-1 sample size (5, 10, 30)
- Level-2 sample size (30, 50, 100, 200)
- Observed indicator ICC (.1, .3, .5)
- Latent variable ICC (.1, .5)
## level-1 Sample size
ss_l1 <- c(5, 10, 30) ## 6 conditions each
ss_l2 <- c(30, 50, 100, 200) ## 18 condition each
icc_ov <- c(.1, .3, .5) ## 2 conditions each
icc_lv <- c(.1, .5) ## every other condition
nCon <- 72 # number of conditions
nRep <- 500 # number of replications per condition
nMod <- 12 ## numberof estimated models per conditions
## Total number of rows: 432,000
ss_l2 <- c(rep(ss_l2[1], 18*nRep*nMod), rep(ss_l2[2], 18*nRep*nMod), rep(ss_l2[3], 18*nRep*nMod), rep(ss_l2[4], 18*nRep*nMod))
ss_l1 <- rep(c(rep(ss_l1[1],6*nRep*nMod), rep(ss_l1[2],6*nRep*nMod), rep(ss_l1[3],6*nRep*nMod)), 4)
icc_ov <- rep(c(rep(icc_ov[1], 2*nRep*nMod), rep(icc_ov[2], 2*nRep*nMod), rep(icc_ov[3], 2*nRep*nMod)), 12)
icc_lv <- rep(c(rep(icc_lv[1], nRep*nMod), rep(icc_lv[2], nRep*nMod)), 36)
## Force these vectors to be column vectors
ss_l1 <- matrix(ss_l1, ncol=1)
ss_l2 <- matrix(ss_l2, ncol=1)
icc_ov <- matrix(icc_ov, ncol=1)
icc_lv <- matrix(icc_lv, ncol=1)
## Add the labels to the results data frame
sim_results <- sim_results[order(sim_results$Condition),]
sim_results <- cbind(sim_results, ss_l1, ss_l2, icc_ov, icc_lv)
## Force the conditions to be factors
sim_results$ss_l1 <- as.factor(sim_results$ss_l1)
sim_results$ss_l2 <- as.factor(sim_results$ss_l2)
sim_results$icc_ov <- as.factor(sim_results$icc_ov)
sim_results$icc_lv <- as.factor(sim_results$icc_lv)
sim_results$Model <- factor(sim_results$Model, levels = c('C','M1','M2','M12'), ordered = T)
## Subset to the usable cases
sim_results <- filter(sim_results, Converge == 1 & Admissible == 1)ANOVA and effect sizes for distributional differences
One of the key outcomes for this large simulation was how the distribution of fit indices changes due to manipulating the design factor. So, for this simulation experiment, there were 6 factors systematically varied. Of these 6 factors, 4 were factors influencing the observed data and 2 were factors pertaining to estimation and model fitting. The factors were
- Level-1 sample size (5, 10, 30)
- Level-2 sample size (30, 50, 100, 200)
- Observed indicator ICC (.1, .3, .5)
- Latent variable ICC (.1, .5)
- Model specification (C, M1, M2, M12)
- Model estimator (MLR, ULSMV, WLSMV)
For each fit statistic, an analysis of variance (ANOVA) was conducted in order to test how much influence each of these design factors had on the distribution of the fit indice.
General Linear Model investigated for fit measures was: \[ Y_{ijklmno} = \mu + \alpha_{j} + \beta_{k} + \gamma_{l} + \delta_m + \zeta_n + \theta_o +\\ (\alpha\beta)_{jk} + (\alpha\gamma)_{jl}+ (\alpha\delta)_{jm} + (\alpha\zeta)_{jn} + (\alpha\theta)_{jo}+ \\ (\beta\gamma)_{kl}+ (\beta\delta)_{km} + (\beta\zeta)_{kn} + (\beta\theta)_{ko}+ (\gamma\delta)_{lm} +\\ (\gamma\zeta)_{ln} + (\gamma\theta)_{lo} +(\delta\zeta)_{mn} + (\delta\theta)_{mo} + (\zeta\theta)_{no} + \varepsilon_{ijklmno} \] where
- \(\mu\) is the grand mean,
- \(\alpha_{j}\) is the effect of Level-1 sample size,
- \(\beta_{k}\) is the effect of Level-2 sample size,
- \(\gamma_{l}\) is the effect of Observed indicator ICC,
- \(\delta_m\) is the effect of Latent variable ICC,
- \(\zeta_n\) is the effect of Model specification,
- \(\theta_o\) is the effect of Model estimator ,
- \((\alpha\beta)_{jk}\) is the interaction between Level-1 sample size and Level-2 sample size,
- \((\alpha\gamma)_{jl}\) is the interaction between Level-1 sample size and Observed indicator ICC,
- \((\alpha\delta)_{jm}\) is the interaction between Level-1 sample size and Latent variable ICC,
- \((\alpha\zeta)_{jn}\) is the interaction between Level-1 sample size and Model specification,
- \((\alpha\theta)_{jo}\) is the interaction between Level-1 sample size and Model estimator ,
- \((\beta\gamma)_{kl}\) is the interaction between Level-2 sample size and Observed indicator ICC,
- \((\beta\delta)_{km}\) is the interaction between Level-2 sample size and Latent variable ICC,
- \((\beta\zeta)_{kn}\) is the interaction between Level-2 sample size and Model specification,
- \((\beta\theta)_{ko}\) is the interaction between Level-2 sample size and Model estimator ,
- \((\gamma\delta)_{lm}\) is the interaction between Observed indicator ICC and Latent variable ICC,
- \((\gamma\zeta)_{ln}\) is the interaction between Observed indicator ICC and Model specification,
- \((\gamma\theta)_{lo}\) is the interaction between Observed indicator ICC and Model estimator ,
- \((\delta\zeta)_{mn}\) is the interaction between Latent variable ICC and Model specification,
- \((\delta\theta)_{mo}\) is the interaction between Latent variable ICC and Model estimator ,
- \((\zeta\theta)_{no}\) is the interaction between Model specification and Model estimator , and
- \(\varepsilon_{ijkl}\) is the residual error for the \(i^{th}\) observed fit measure.
Note that for most of these terms there are actually 2 or 3 terms actually estimated. These additional terms are because of the categorical natire of each effect so we have to create “reference” groups and calculate the effect of being in a group other than the reference group. Higher order interactions were omitted for clearity of interpretation of the model. If interested in higher-order interactins, please see Maxwell and Delaney (2004).
The real reason the higher order interaction was omitted: Because I have no clue how to interpret a 6-way interaction (whatever the heck that is), I am limiting the ANOVA to all bivariate interactions.
Diagnostics for factorial ANOVA:
- Independence of Observations
- Normality of residuals across cells for the design
- Homogeneity of variance across cells
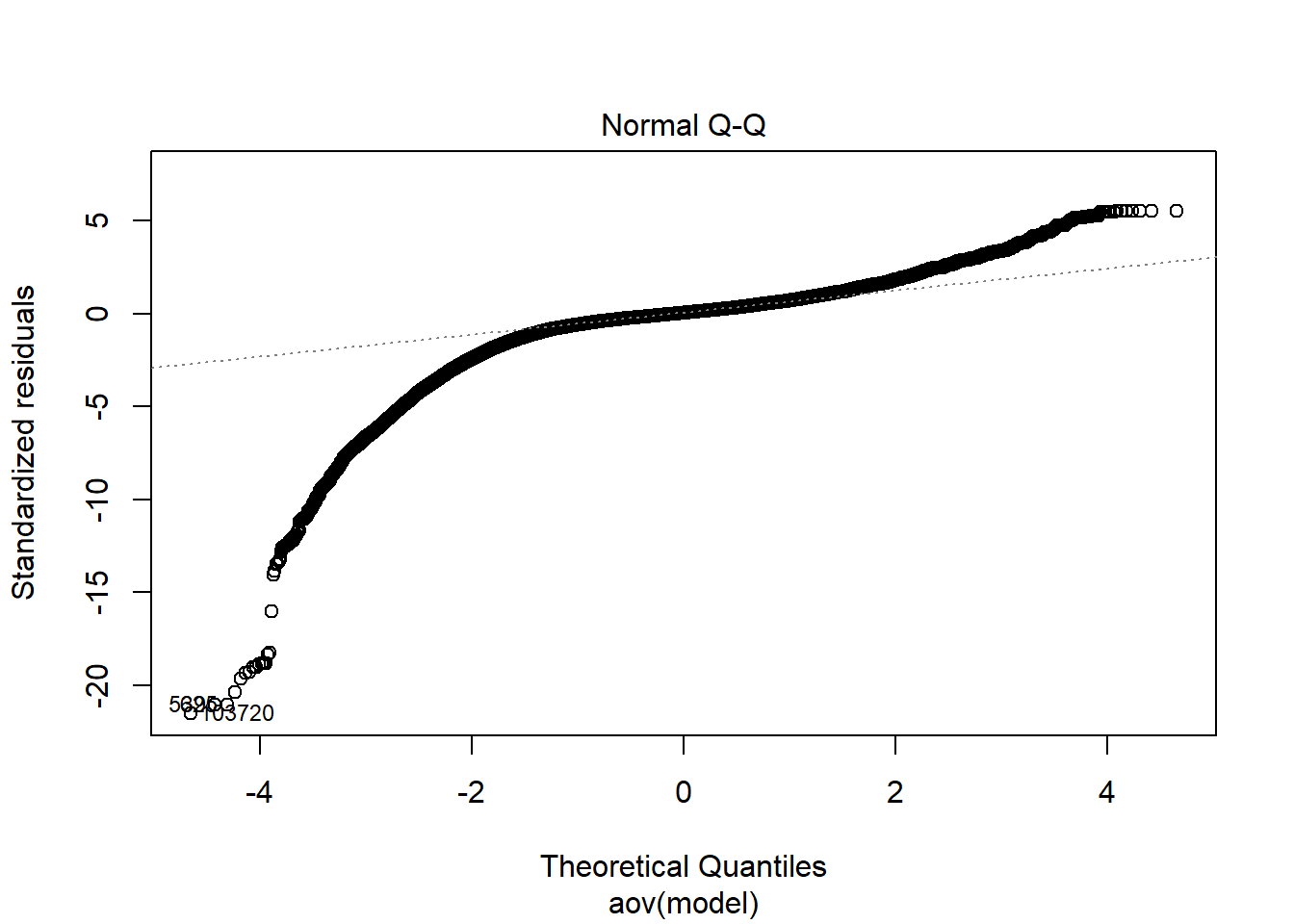
Independence of observations is by design, where these data were randomly generated from a known population and observations are across replications and are independent. The normality assumptions is that the residuals of the models are normally distributed across the design cells. The normality assumption is tested by investigation by Shapiro-Wilks Test, the K-S test, and visual inspection of QQ-plots and histograms. The equality of variance is checked through Levene’s test across all the different conditions/groupings. Furthermore, the plots of the residuals are also indicative of the equality of variance across groups as there should be no apparent pattern to the residual plots.
Assumption Checking
CFI
## model factors...
flist <- c('ss_l1', 'ss_l2', 'icc_ov', 'icc_lv','Model', 'Estimator')
## Check assumptions
anova_assumptions_check(
sim_results, 'CFI', factors = flist,
model = as.formula('CFI ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator'))
=============================
Tests and Plots of Normality:
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
Shapiro-Wilks Test of Normality of Residuals:
Shapiro-Wilk normality test
data: res
W = 0.78436, p-value < 2.2e-16
K-S Test for Normality of Residuals:Warning in ks.test(aov.out$residuals, "pnorm", alternative = "two.sided"):
ties should not be present for the Kolmogorov-Smirnov test
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
One-sample Kolmogorov-Smirnov test
data: aov.out$residuals
D = 0.45839, p-value < 2.2e-16
alternative hypothesis: two-sided`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).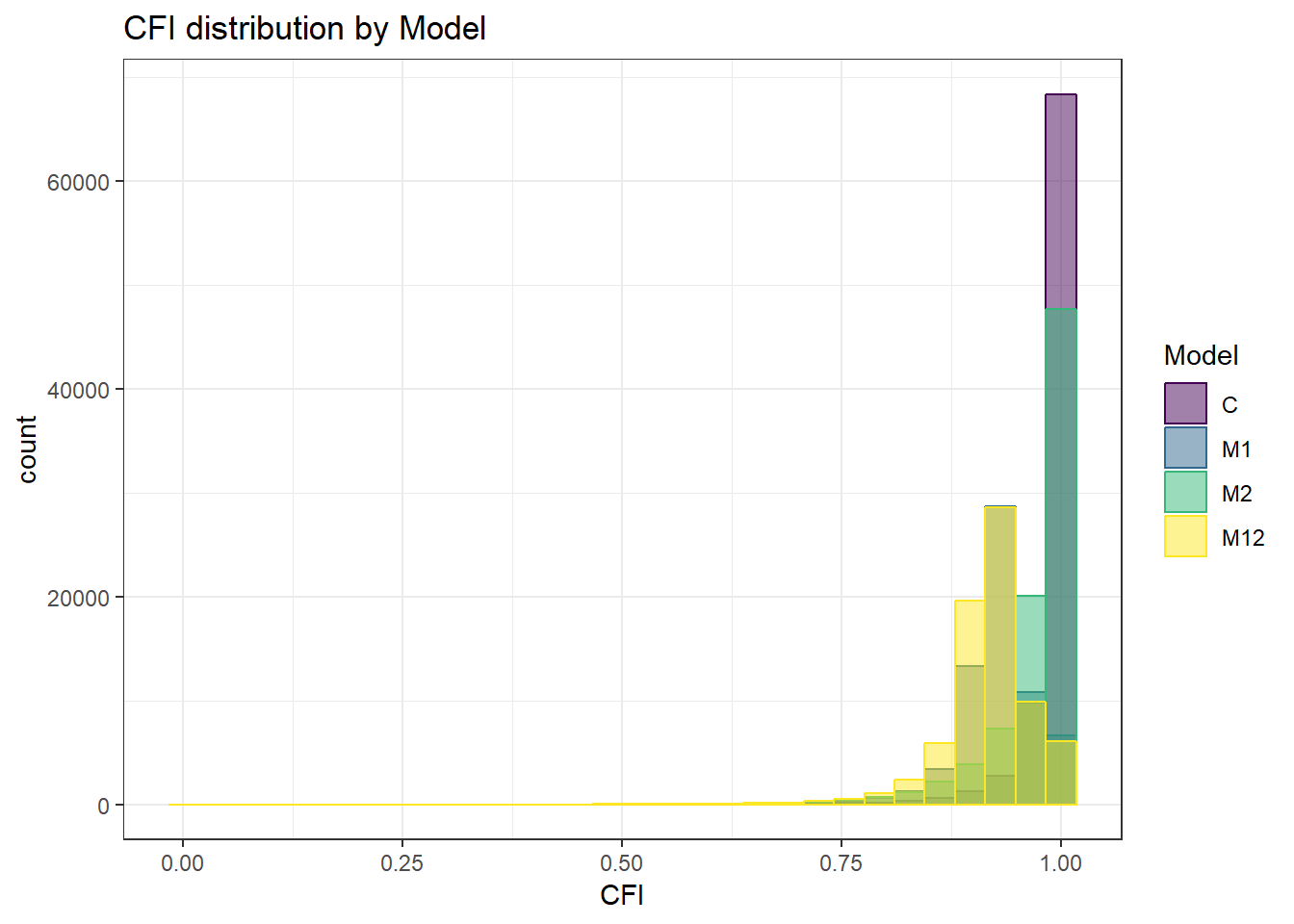
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).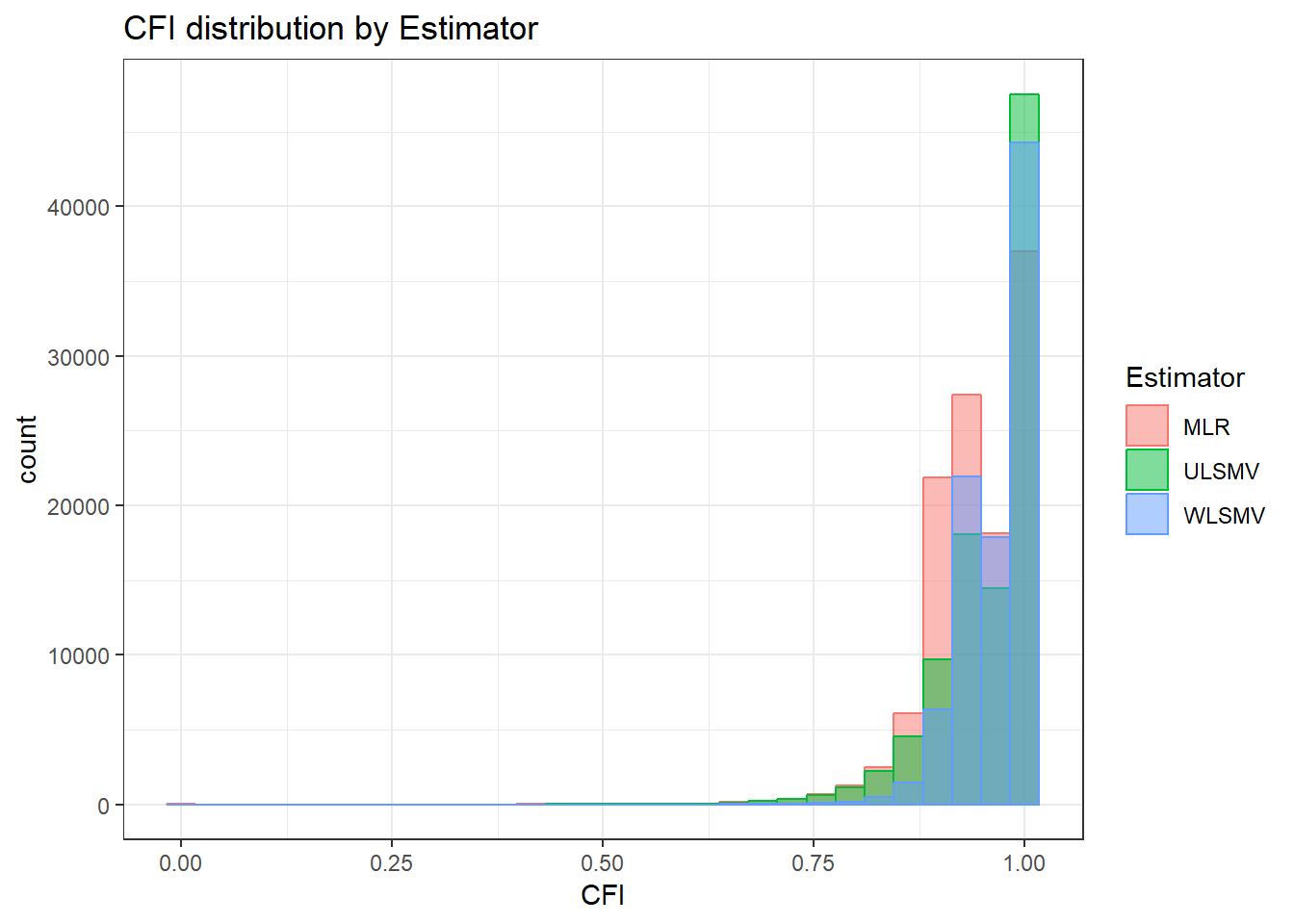
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
=============================
Tests of Homogeneity of Variance
Levenes Test: ss_l1
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 3589.8 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: ss_l2
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 4957.8 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_ov
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 27.465 1.183e-12 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_lv
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 1 1626.5 < 2.2e-16 ***
307265
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Model
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 4958.9 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Estimator
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 4762.4 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1TLI
anova_assumptions_check(
sim_results, 'TLI', factors = flist,
model = as.formula('TLI ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator'))
=============================
Tests and Plots of Normality: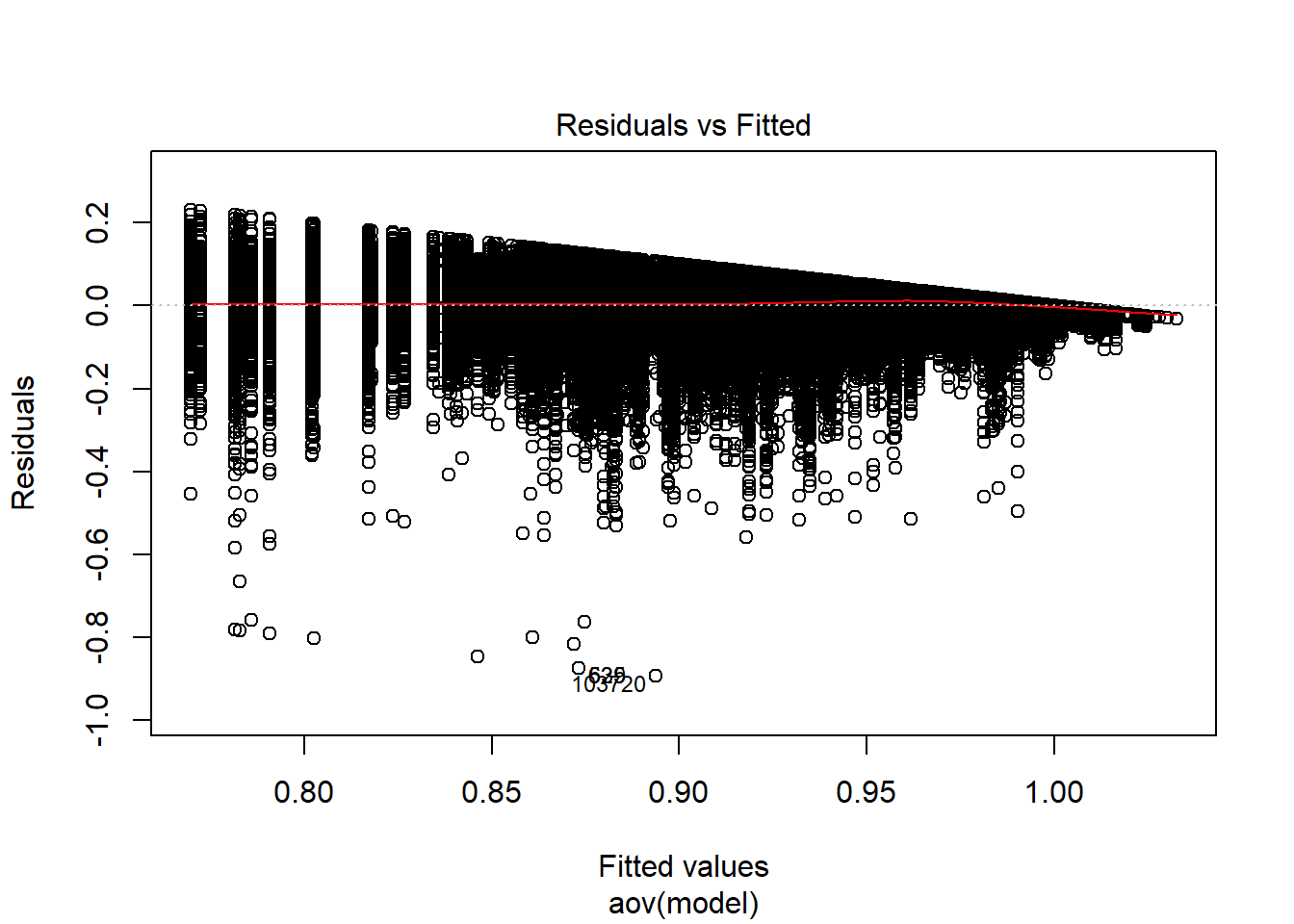
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
Shapiro-Wilks Test of Normality of Residuals:
Shapiro-Wilk normality test
data: res
W = 0.87141, p-value < 2.2e-16
K-S Test for Normality of Residuals:Warning in ks.test(aov.out$residuals, "pnorm", alternative = "two.sided"):
ties should not be present for the Kolmogorov-Smirnov test
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
One-sample Kolmogorov-Smirnov test
data: aov.out$residuals
D = 0.45175, p-value < 2.2e-16
alternative hypothesis: two-sided`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).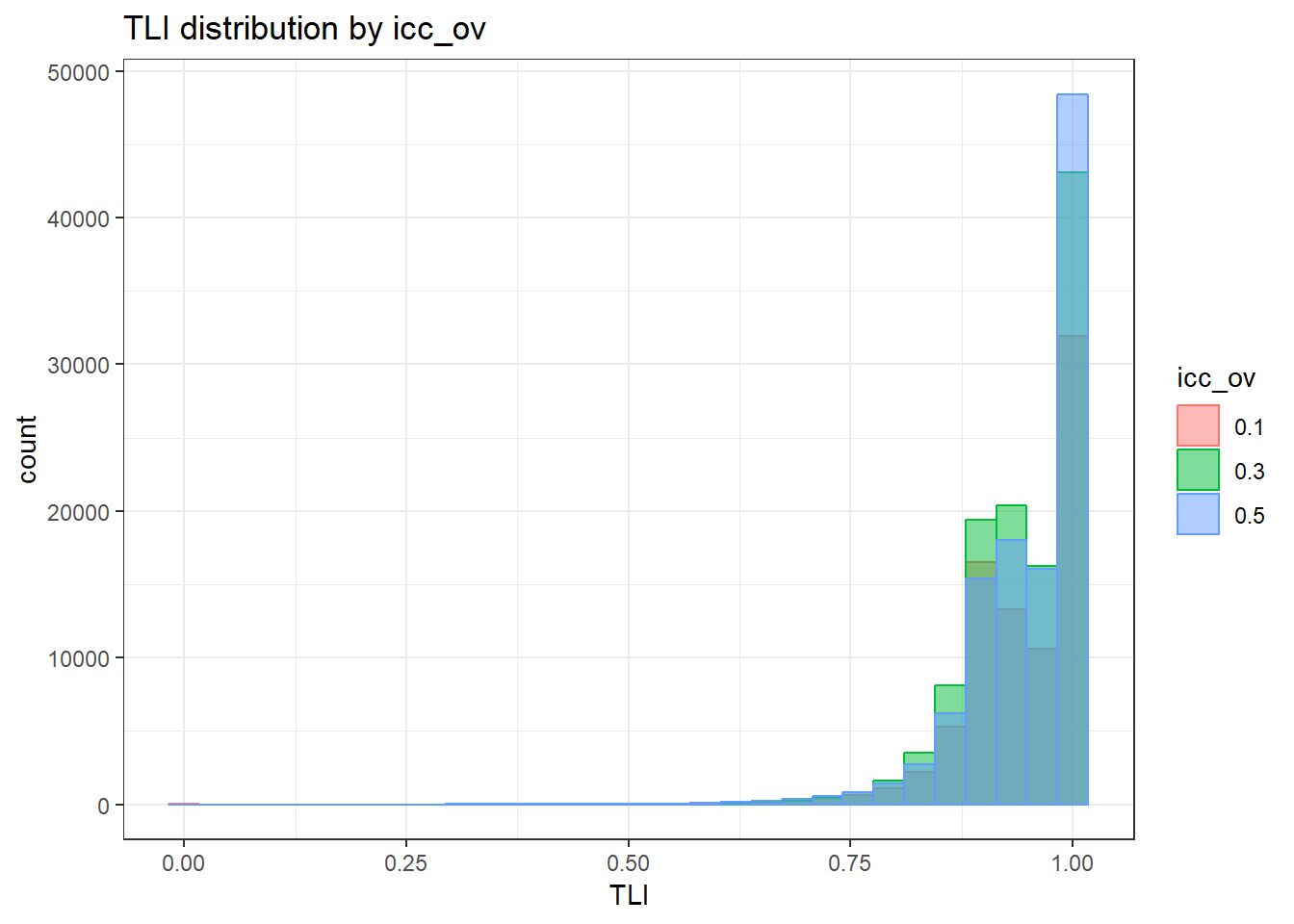
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).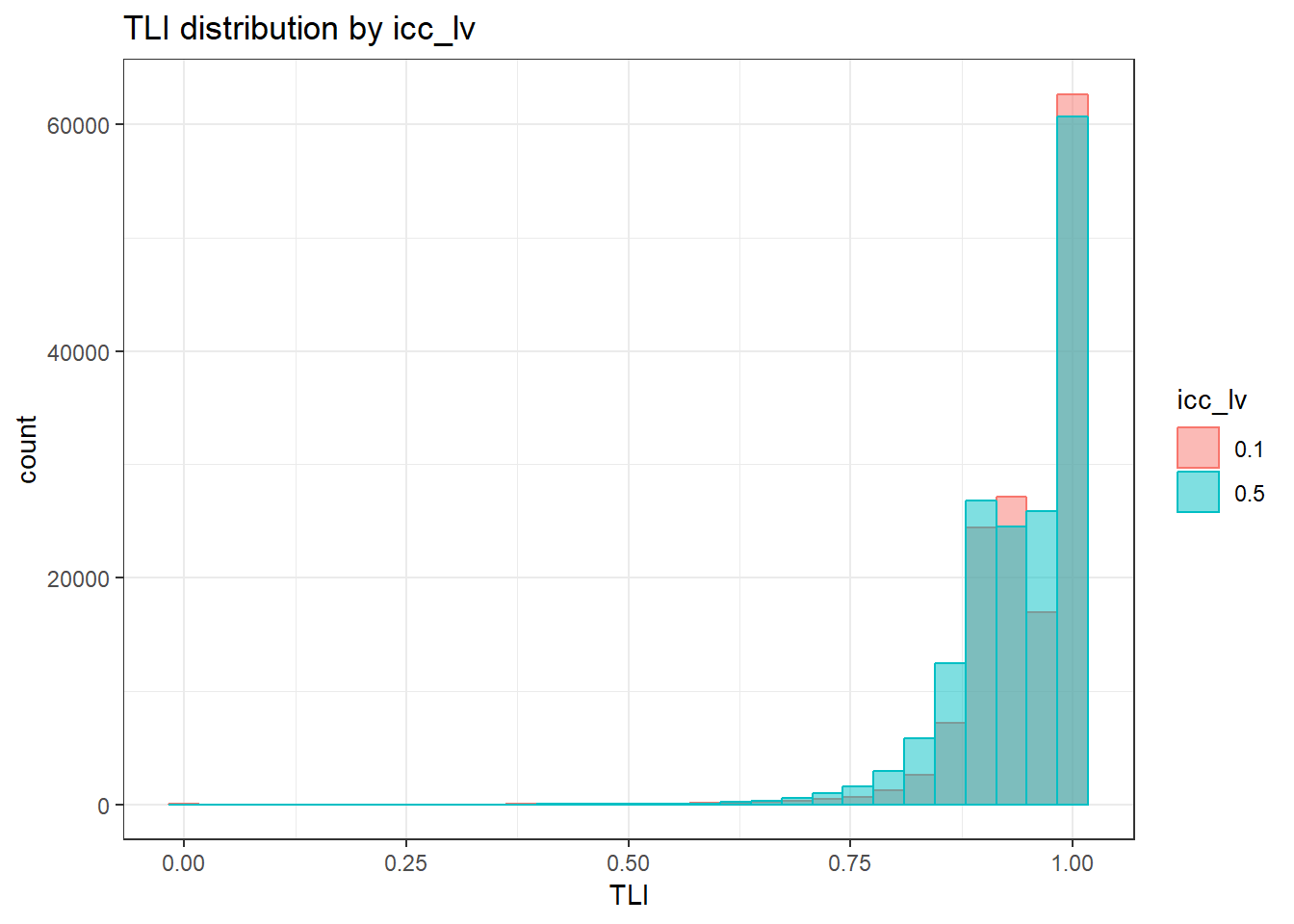
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).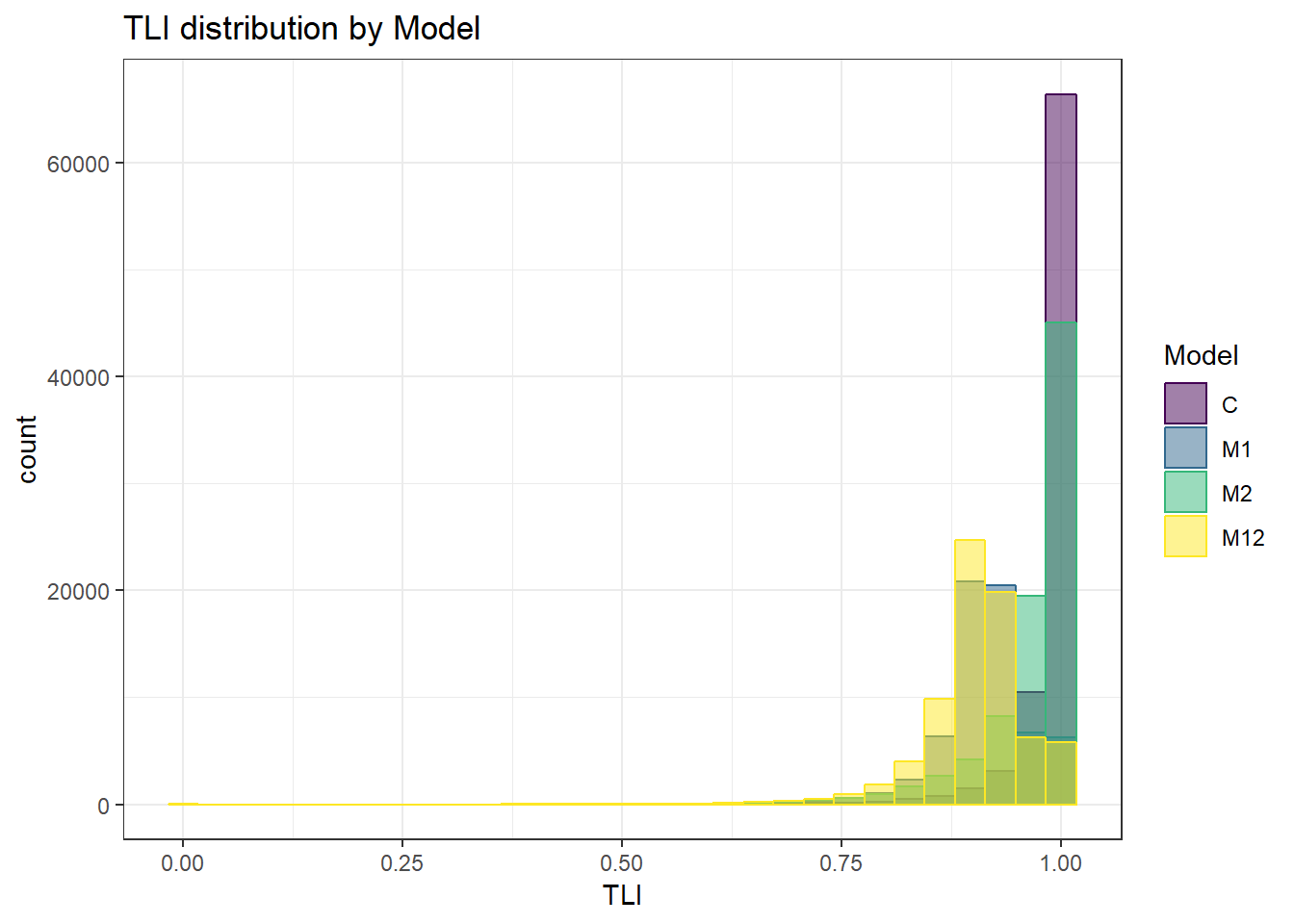
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).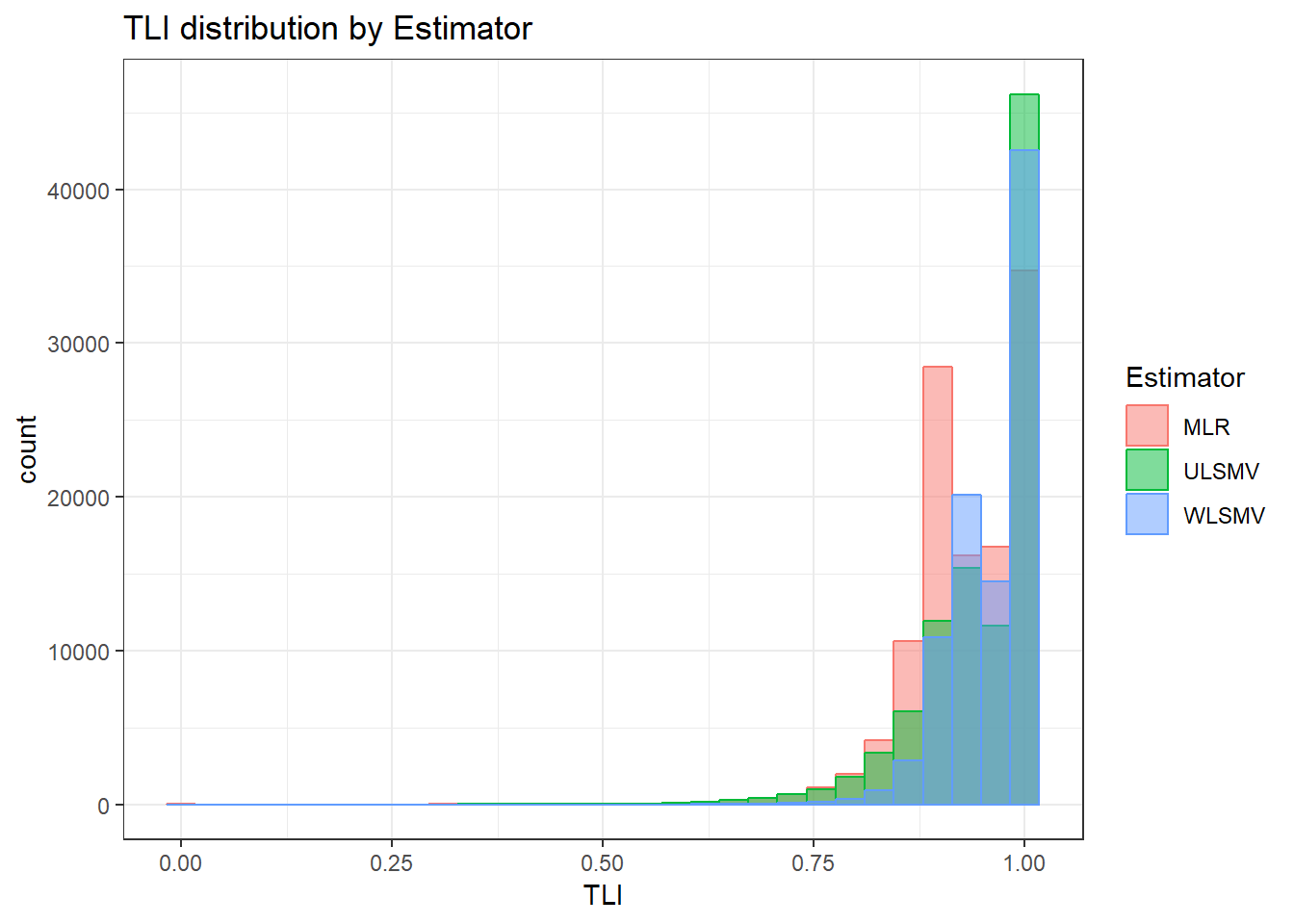
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
=============================
Tests of Homogeneity of Variance
Levenes Test: ss_l1
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 3604.9 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: ss_l2
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 5009.7 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_ov
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 26.835 2.221e-12 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_lv
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 1 1651.9 < 2.2e-16 ***
307265
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Model
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 4912.1 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Estimator
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 4803.2 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1RMSEA
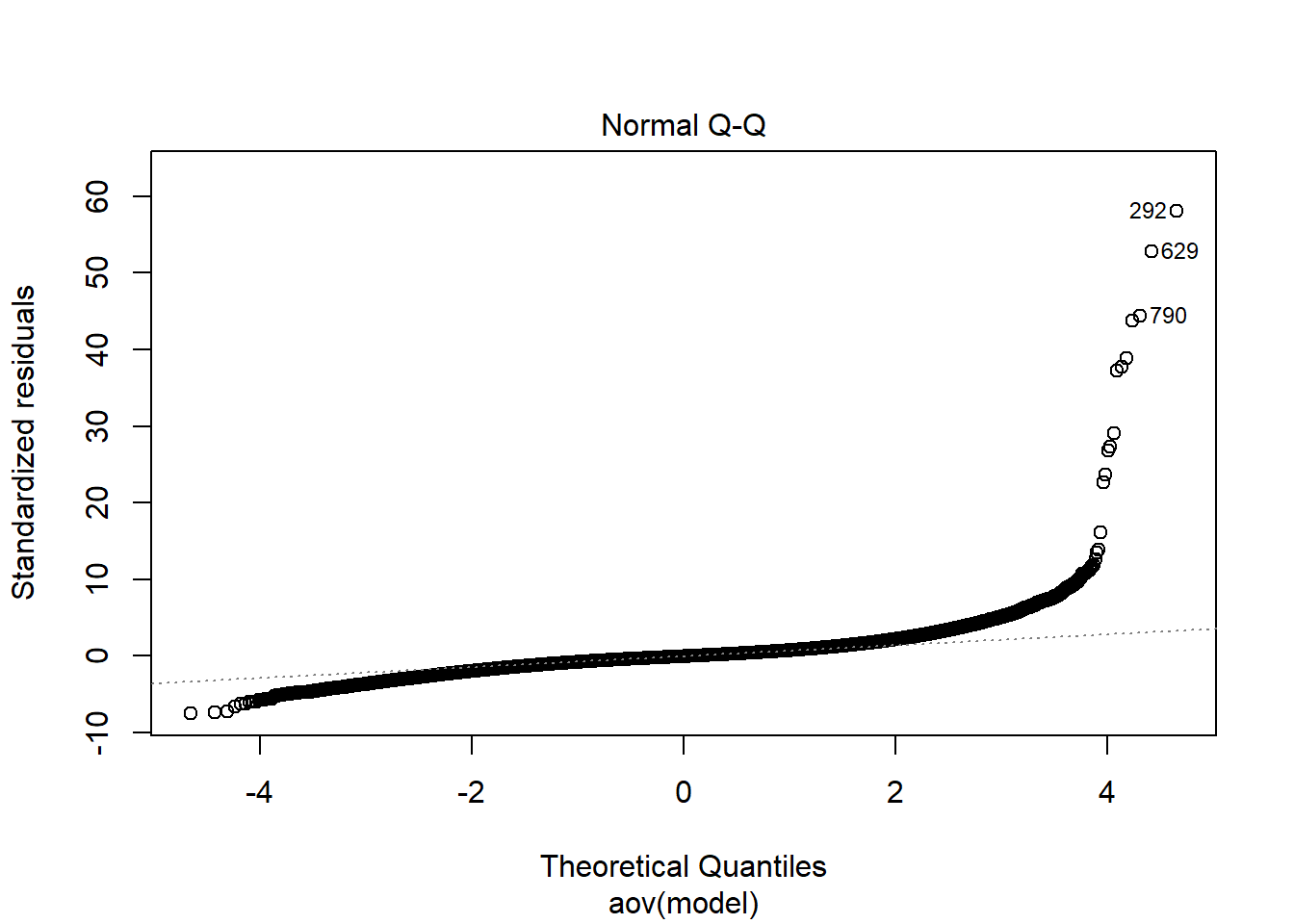
anova_assumptions_check(
sim_results, 'RMSEA', factors = flist,
model = as.formula('RMSEA ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator'))
=============================
Tests and Plots of Normality:
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
Shapiro-Wilks Test of Normality of Residuals:
Shapiro-Wilk normality test
data: res
W = 0.97275, p-value < 2.2e-16
K-S Test for Normality of Residuals:Warning in ks.test(aov.out$residuals, "pnorm", alternative = "two.sided"):
ties should not be present for the Kolmogorov-Smirnov test
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
One-sample Kolmogorov-Smirnov test
data: aov.out$residuals
D = 0.48597, p-value < 2.2e-16
alternative hypothesis: two-sided`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).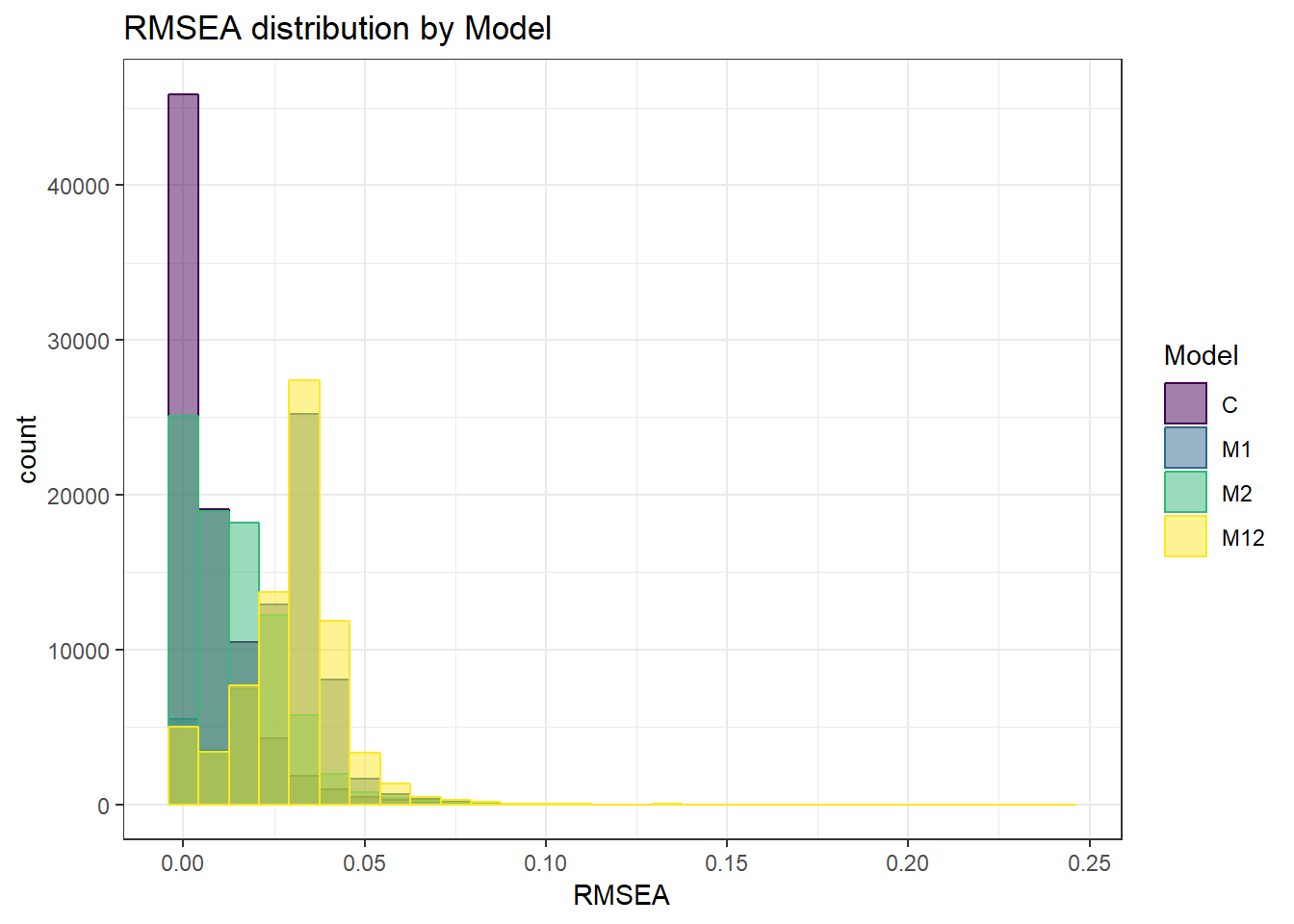
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).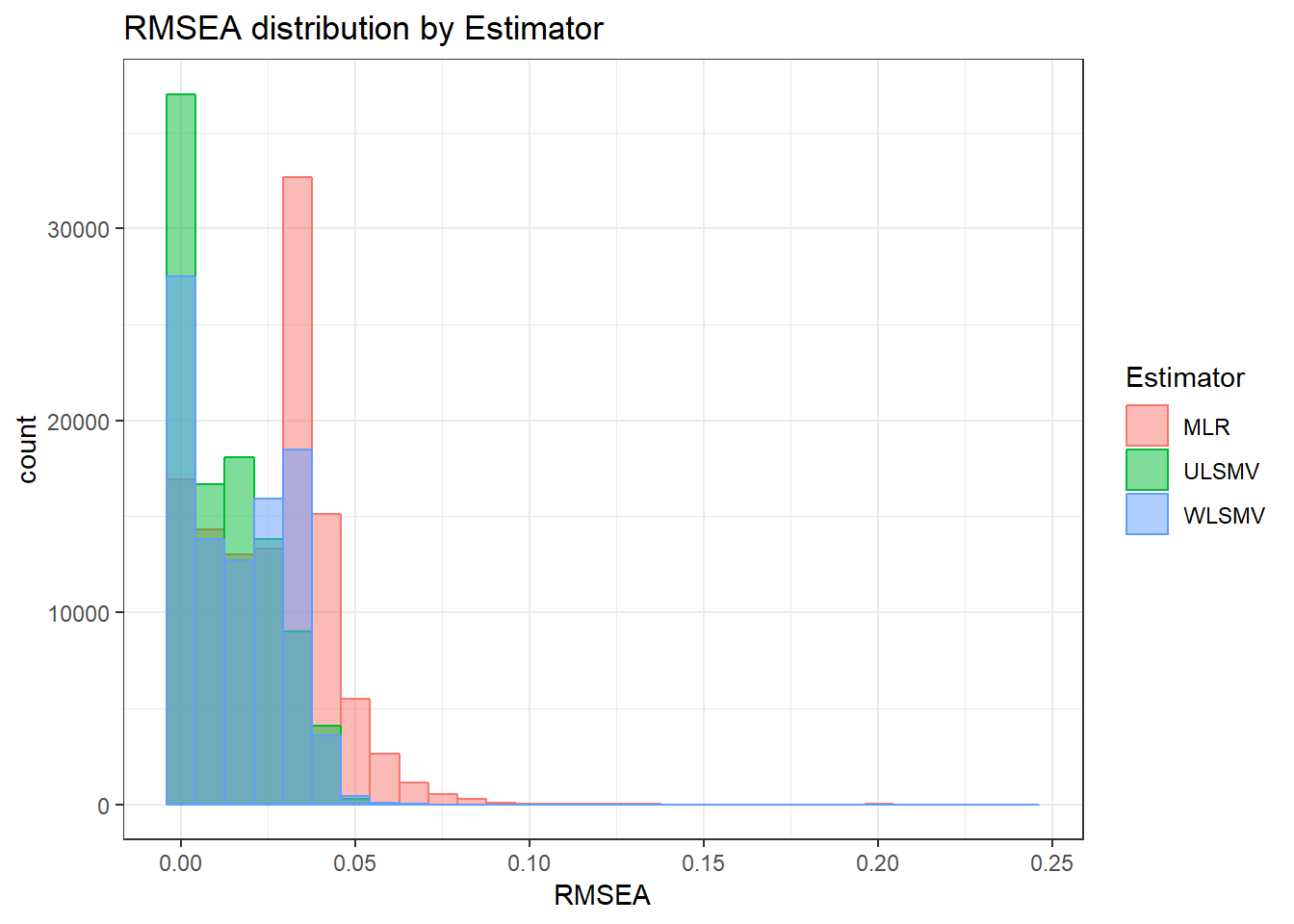
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
=============================
Tests of Homogeneity of Variance
Levenes Test: ss_l1
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 410.32 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: ss_l2
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 4073.6 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_ov
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 2365.2 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_lv
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 1 1.41 0.2351
307265
Levenes Test: Model
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 1570.3 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Estimator
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 4400.9 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1SRMRW
anova_assumptions_check(
sim_results, 'SRMRW', factors = flist,
model = as.formula('SRMRW ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator'))
=============================
Tests and Plots of Normality: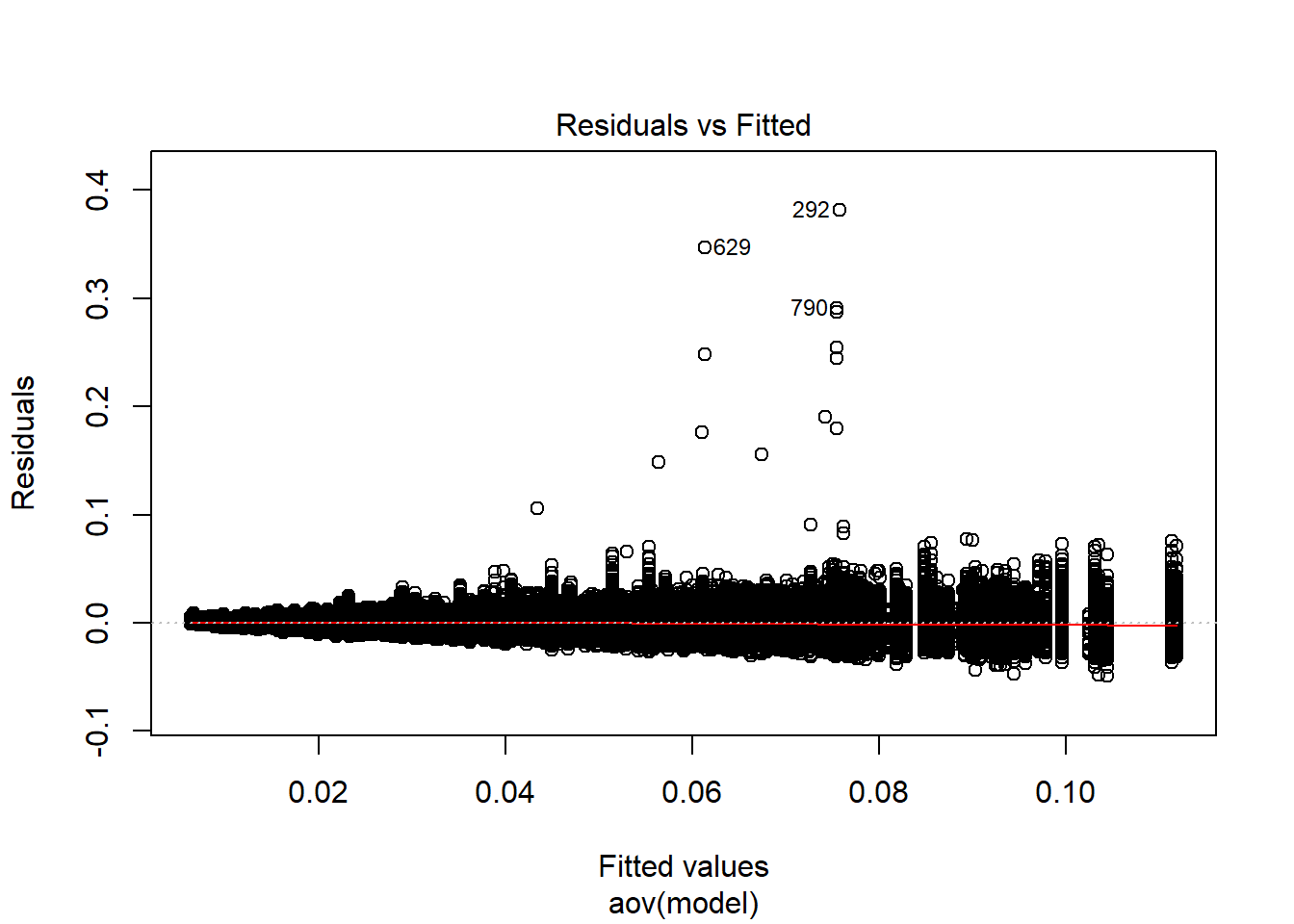
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
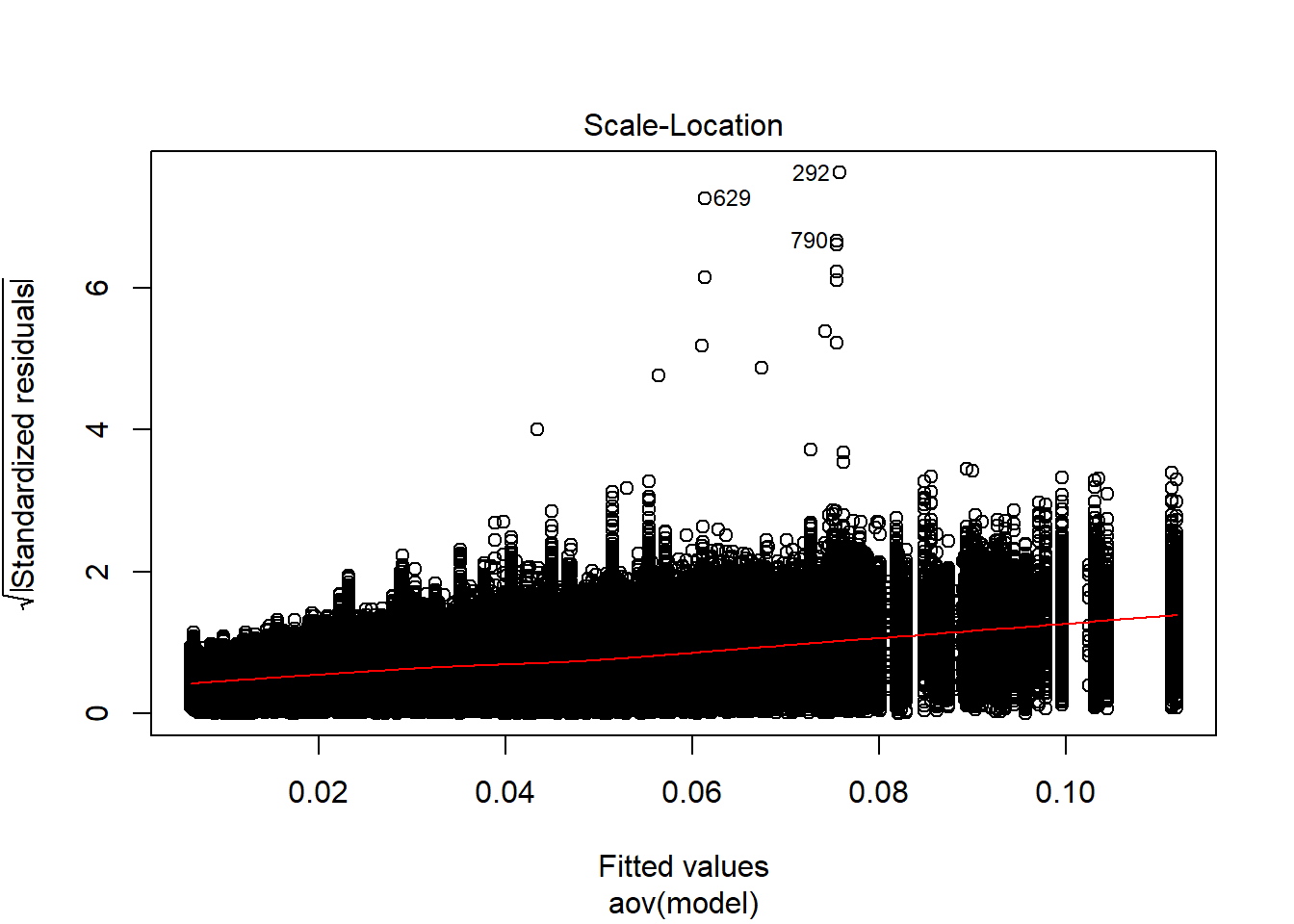
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
Shapiro-Wilks Test of Normality of Residuals:
Shapiro-Wilk normality test
data: res
W = 0.95145, p-value < 2.2e-16
K-S Test for Normality of Residuals:Warning in ks.test(aov.out$residuals, "pnorm", alternative = "two.sided"):
ties should not be present for the Kolmogorov-Smirnov test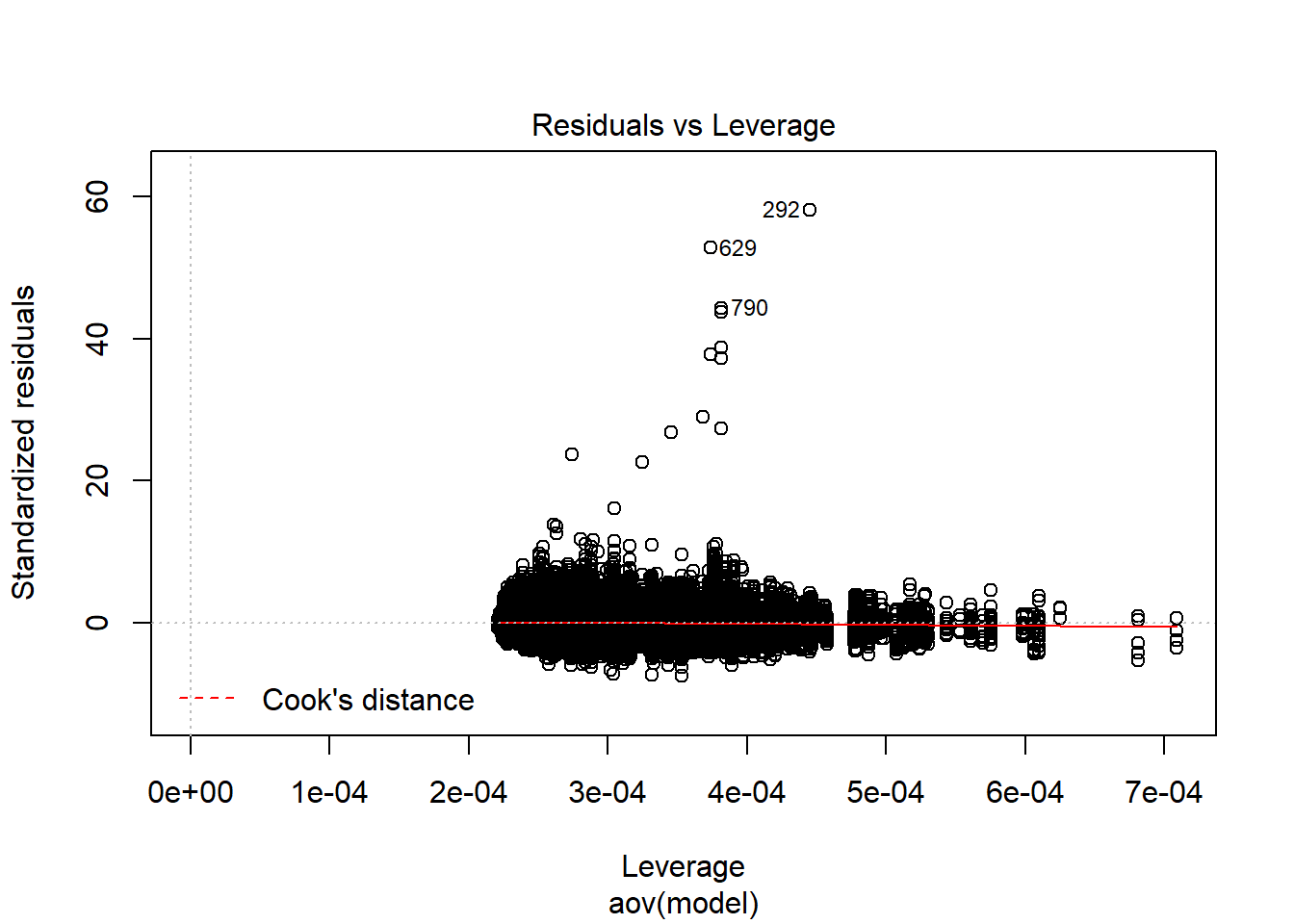
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
One-sample Kolmogorov-Smirnov test
data: aov.out$residuals
D = 0.48914, p-value < 2.2e-16
alternative hypothesis: two-sided`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
=============================
Tests of Homogeneity of Variance
Levenes Test: ss_l1
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 1193.9 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: ss_l2
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 2255.5 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_ov
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 1345.8 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_lv
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 1 1446.7 < 2.2e-16 ***
307265
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Model
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 2758.5 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Estimator
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 3272.8 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1SRMRB
anova_assumptions_check(
sim_results, 'SRMRB', factors = flist,
model = as.formula('SRMRB ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator'))
=============================
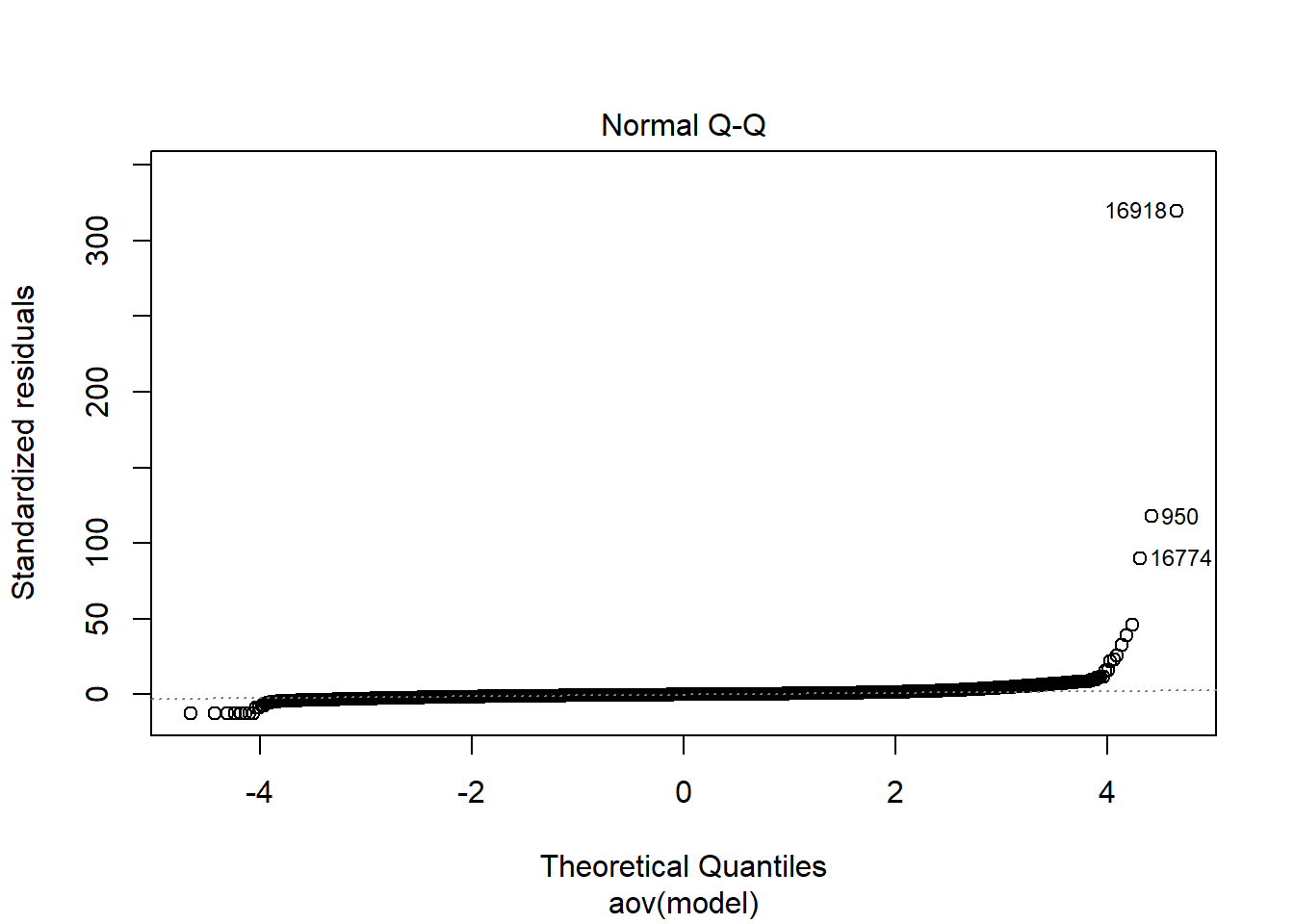
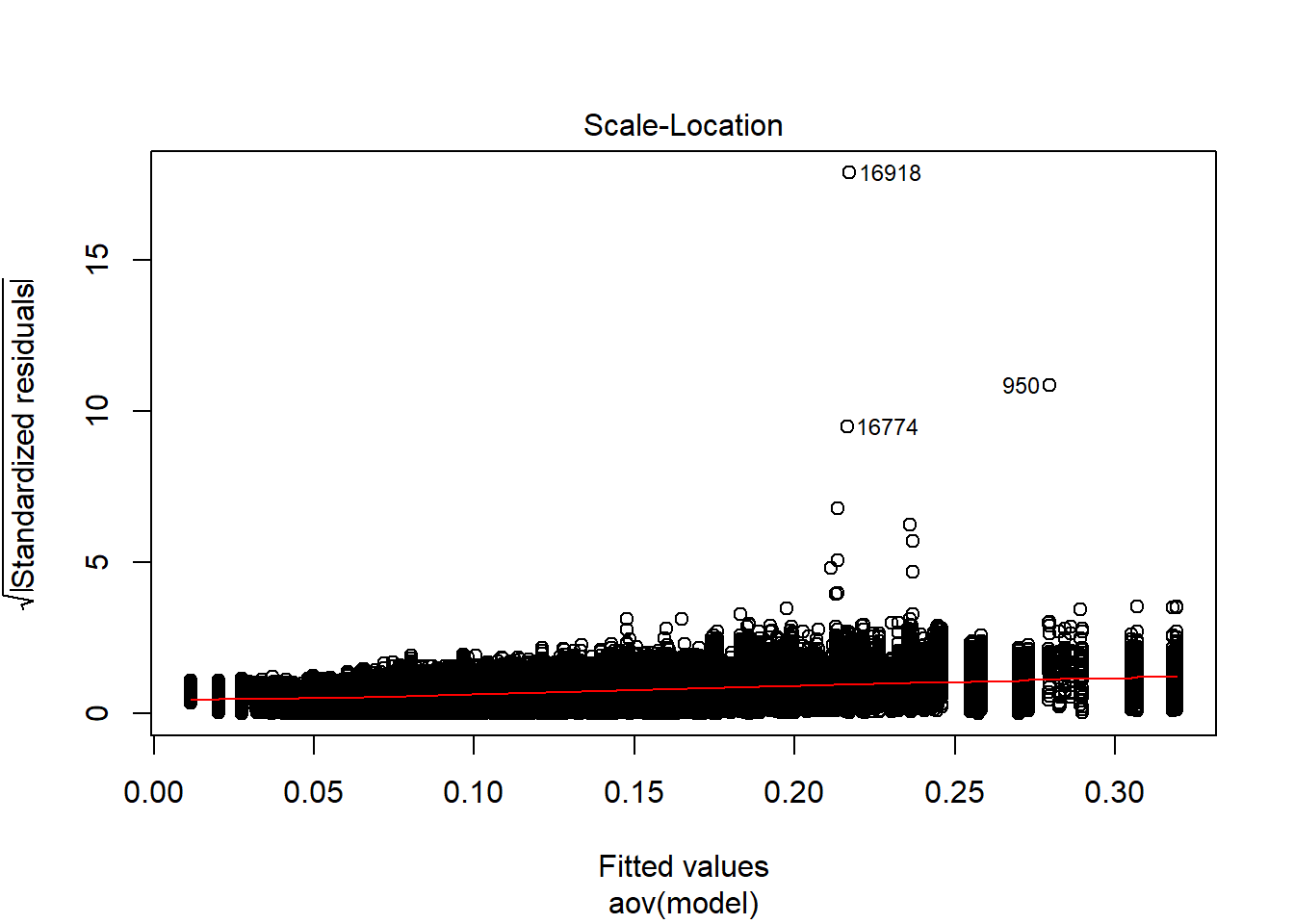
Tests and Plots of Normality: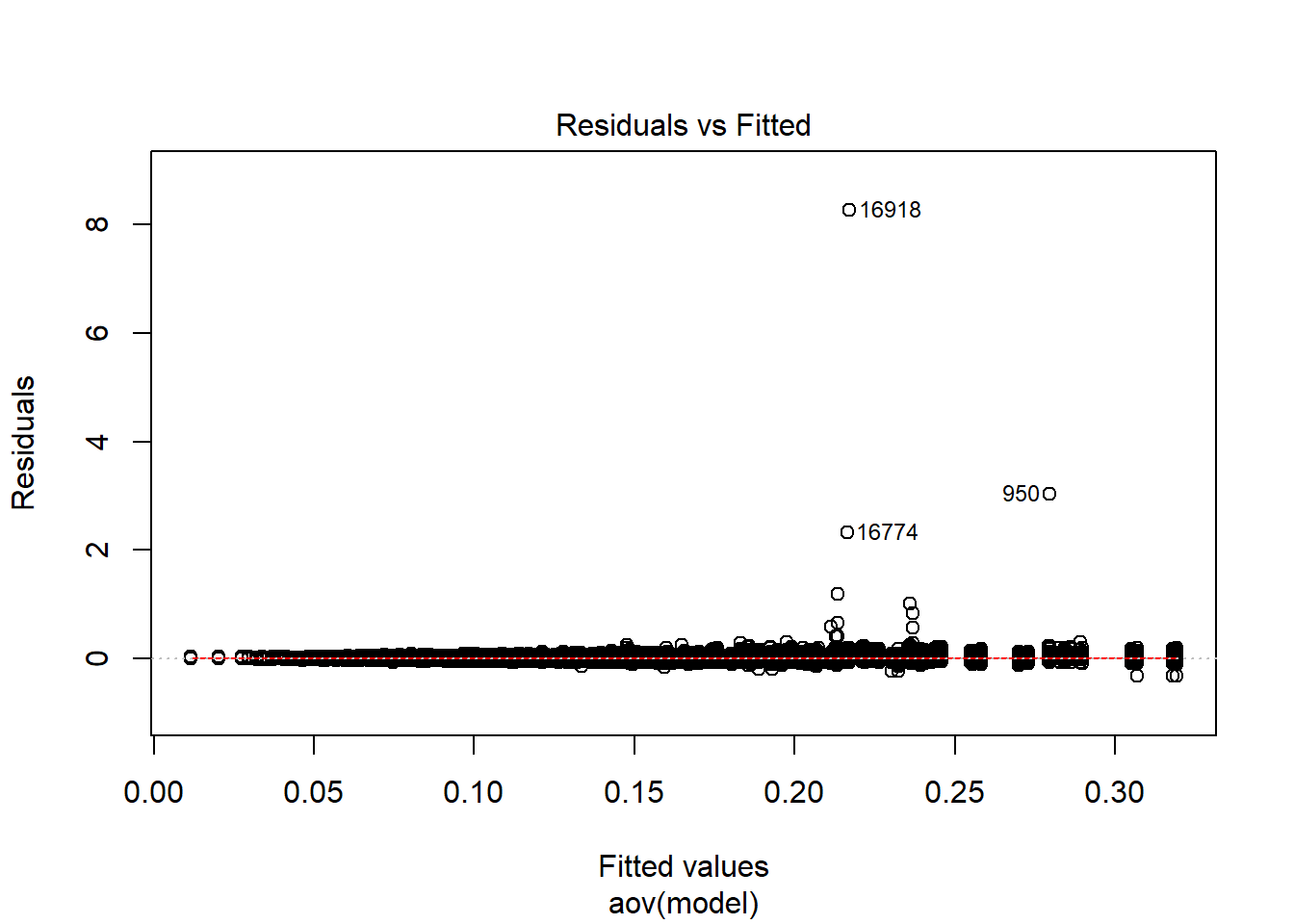
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
Shapiro-Wilks Test of Normality of Residuals:
Shapiro-Wilk normality test
data: res
W = 0.92039, p-value < 2.2e-16
K-S Test for Normality of Residuals:Warning in ks.test(aov.out$residuals, "pnorm", alternative = "two.sided"):
ties should not be present for the Kolmogorov-Smirnov test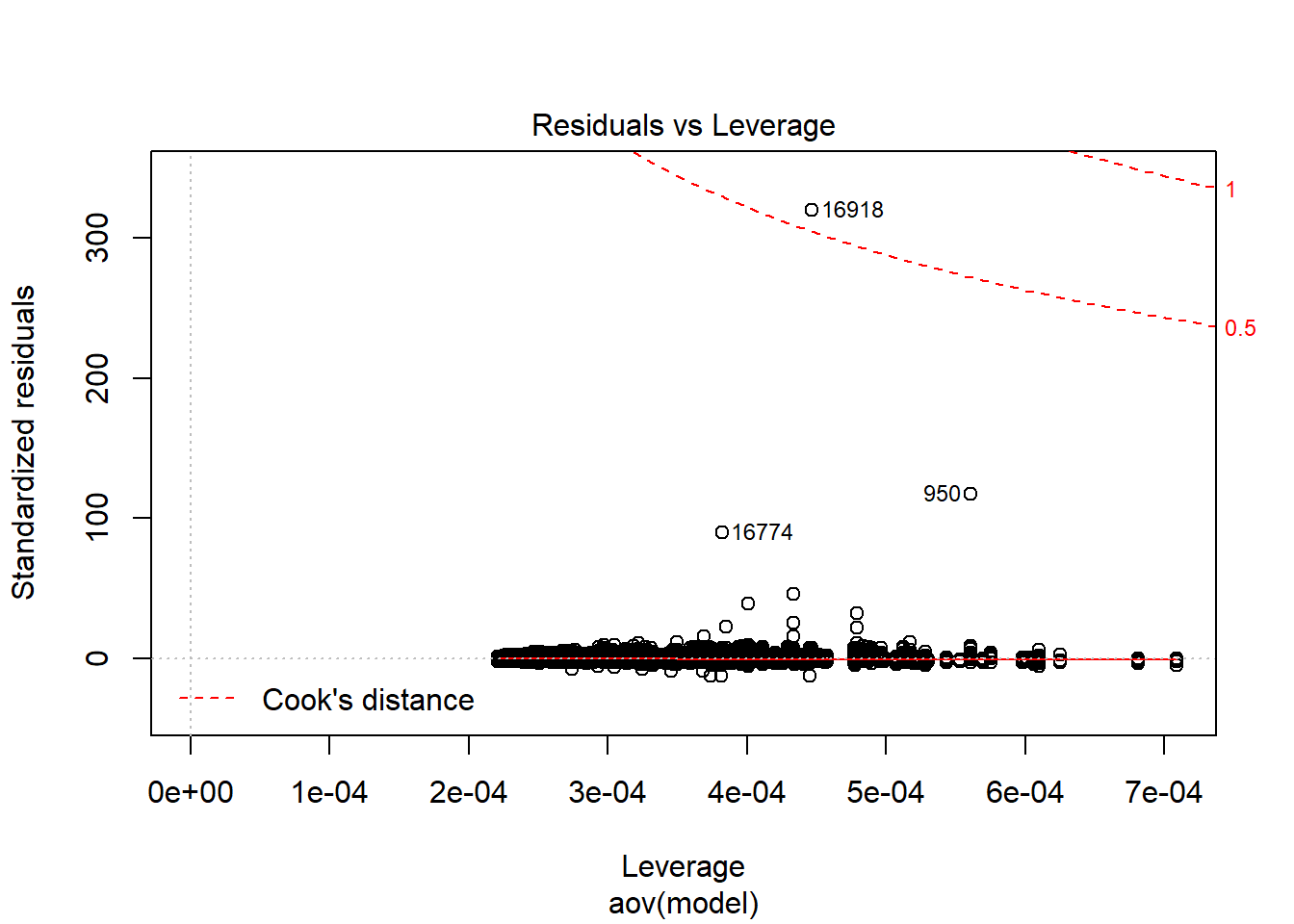
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
One-sample Kolmogorov-Smirnov test
data: aov.out$residuals
D = 0.47316, p-value < 2.2e-16
alternative hypothesis: two-sided`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.Warning: Removed 111 rows containing non-finite values (stat_bin).
| Version | Author | Date |
|---|---|---|
| fb03a30 | noah-padgett | 2019-05-09 |
=============================
Tests of Homogeneity of Variance
Levenes Test: ss_l1
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 4683.8 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: ss_l2
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 2531.7 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_ov
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 8813.7 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: icc_lv
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 1 12256 < 2.2e-16 ***
307265
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Model
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 3 112.29 < 2.2e-16 ***
307263
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Levenes Test: Estimator
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 2 1871.3 < 2.2e-16 ***
307264
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1ANOVA Analyses
CFI
model <- as.formula('CFI ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator')
fit <- aov(model, data = sim_results)
fit.out <- summary(fit)
fit.out Df Sum Sq Mean Sq F value Pr(>F)
ss_l1 2 34.0 16.99 14004.7 <2e-16 ***
ss_l2 3 10.9 3.65 3005.9 <2e-16 ***
icc_ov 2 4.2 2.10 1734.5 <2e-16 ***
icc_lv 1 3.7 3.65 3009.1 <2e-16 ***
Model 3 268.1 89.37 73671.1 <2e-16 ***
Estimator 2 19.9 9.96 8212.8 <2e-16 ***
ss_l1:ss_l2 6 30.6 5.10 4203.9 <2e-16 ***
ss_l1:icc_ov 4 4.0 0.99 815.4 <2e-16 ***
ss_l1:icc_lv 2 0.4 0.21 169.2 <2e-16 ***
ss_l1:Model 6 0.9 0.14 119.5 <2e-16 ***
ss_l1:Estimator 4 1.3 0.34 276.2 <2e-16 ***
ss_l2:icc_ov 6 1.2 0.19 158.6 <2e-16 ***
ss_l2:icc_lv 3 4.7 1.56 1289.5 <2e-16 ***
ss_l2:Model 9 2.6 0.29 239.2 <2e-16 ***
ss_l2:Estimator 6 28.7 4.79 3948.8 <2e-16 ***
icc_ov:icc_lv 2 2.6 1.30 1072.7 <2e-16 ***
icc_ov:Model 6 5.9 0.99 816.6 <2e-16 ***
icc_ov:Estimator 4 5.3 1.32 1084.2 <2e-16 ***
icc_lv:Model 3 15.3 5.11 4214.2 <2e-16 ***
icc_lv:Estimator 2 11.1 5.57 4588.7 <2e-16 ***
Model:Estimator 6 16.8 2.80 2310.3 <2e-16 ***
Residuals 307184 372.7 0.00
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
111 observations deleted due to missingnesscfi.out <- cbind(omega2(fit.out),p_omega2(fit.out))
cfi.out omega^2 partial-omega^2
ss_l1 0.0402 0.0835
ss_l2 0.0129 0.0285
icc_ov 0.0050 0.0112
icc_lv 0.0043 0.0097
Model 0.3173 0.4184
Estimator 0.0236 0.0507
ss_l1:ss_l2 0.0362 0.0758
ss_l1:icc_ov 0.0047 0.0105
ss_l1:icc_lv 0.0005 0.0011
ss_l1:Model 0.0010 0.0023
ss_l1:Estimator 0.0016 0.0036
ss_l2:icc_ov 0.0014 0.0031
ss_l2:icc_lv 0.0055 0.0124
ss_l2:Model 0.0031 0.0069
ss_l2:Estimator 0.0340 0.0716
icc_ov:icc_lv 0.0031 0.0069
icc_ov:Model 0.0070 0.0157
icc_ov:Estimator 0.0062 0.0139
icc_lv:Model 0.0181 0.0395
icc_lv:Estimator 0.0132 0.0290
Model:Estimator 0.0199 0.0431TLI
model <- as.formula('TLI ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator')
fit <- aov(model, data = sim_results)
fit.out <- summary(fit)
fit.out Df Sum Sq Mean Sq F value Pr(>F)
ss_l1 2 48.5 24.23 14068.8 <2e-16 ***
ss_l2 3 15.6 5.21 3024.8 <2e-16 ***
icc_ov 2 6.0 2.98 1731.7 <2e-16 ***
icc_lv 1 5.3 5.25 3050.4 <2e-16 ***
Model 3 377.9 125.97 73129.1 <2e-16 ***
Estimator 2 28.4 14.18 8229.9 <2e-16 ***
ss_l1:ss_l2 6 43.7 7.28 4223.7 <2e-16 ***
ss_l1:icc_ov 4 5.7 1.42 822.6 <2e-16 ***
ss_l1:icc_lv 2 0.6 0.29 169.5 <2e-16 ***
ss_l1:Model 6 1.2 0.20 113.7 <2e-16 ***
ss_l1:Estimator 4 1.9 0.48 276.5 <2e-16 ***
ss_l2:icc_ov 6 1.6 0.27 155.9 <2e-16 ***
ss_l2:icc_lv 3 6.7 2.23 1295.7 <2e-16 ***
ss_l2:Model 9 3.8 0.42 244.7 <2e-16 ***
ss_l2:Estimator 6 41.0 6.84 3969.2 <2e-16 ***
icc_ov:icc_lv 2 3.8 1.88 1088.8 <2e-16 ***
icc_ov:Model 6 8.4 1.41 816.2 <2e-16 ***
icc_ov:Estimator 4 7.5 1.89 1094.7 <2e-16 ***
icc_lv:Model 3 22.1 7.36 4270.3 <2e-16 ***
icc_lv:Estimator 2 15.9 7.96 4623.3 <2e-16 ***
Model:Estimator 6 24.0 4.00 2320.9 <2e-16 ***
Residuals 307184 529.1 0.00
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
111 observations deleted due to missingnesstli.out <- cbind(omega2(fit.out),p_omega2(fit.out))
tli.out omega^2 partial-omega^2
ss_l1 0.0404 0.0839
ss_l2 0.0130 0.0287
icc_ov 0.0050 0.0111
icc_lv 0.0044 0.0098
Model 0.3153 0.4166
Estimator 0.0237 0.0508
ss_l1:ss_l2 0.0364 0.0762
ss_l1:icc_ov 0.0047 0.0106
ss_l1:icc_lv 0.0005 0.0011
ss_l1:Model 0.0010 0.0022
ss_l1:Estimator 0.0016 0.0036
ss_l2:icc_ov 0.0013 0.0030
ss_l2:icc_lv 0.0056 0.0125
ss_l2:Model 0.0032 0.0071
ss_l2:Estimator 0.0342 0.0719
icc_ov:icc_lv 0.0031 0.0070
icc_ov:Model 0.0070 0.0157
icc_ov:Estimator 0.0063 0.0140
icc_lv:Model 0.0184 0.0400
icc_lv:Estimator 0.0133 0.0292
Model:Estimator 0.0200 0.0433RMSEA
model <- as.formula('RMSEA ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator')
fit <- aov(model, data = sim_results)
fit.out <- summary(fit)
fit.out Df Sum Sq Mean Sq F value Pr(>F)
ss_l1 2 3.873 1.937 29985.6 <2e-16 ***
ss_l2 3 0.464 0.155 2392.8 <2e-16 ***
icc_ov 2 3.218 1.609 24911.6 <2e-16 ***
icc_lv 1 0.171 0.171 2640.7 <2e-16 ***
Model 3 29.709 9.903 153329.0 <2e-16 ***
Estimator 2 6.991 3.496 54124.3 <2e-16 ***
ss_l1:ss_l2 6 1.262 0.210 3255.6 <2e-16 ***
ss_l1:icc_ov 4 0.094 0.023 363.6 <2e-16 ***
ss_l1:icc_lv 2 0.189 0.094 1460.1 <2e-16 ***
ss_l1:Model 6 0.202 0.034 522.1 <2e-16 ***
ss_l1:Estimator 4 0.070 0.017 269.3 <2e-16 ***
ss_l2:icc_ov 6 0.411 0.068 1059.3 <2e-16 ***
ss_l2:icc_lv 3 0.103 0.034 529.8 <2e-16 ***
ss_l2:Model 9 0.891 0.099 1533.4 <2e-16 ***
ss_l2:Estimator 6 3.478 0.580 8976.3 <2e-16 ***
icc_ov:icc_lv 2 0.156 0.078 1209.6 <2e-16 ***
icc_ov:Model 6 1.316 0.219 3396.0 <2e-16 ***
icc_ov:Estimator 4 0.867 0.217 3357.5 <2e-16 ***
icc_lv:Model 3 1.437 0.479 7415.3 <2e-16 ***
icc_lv:Estimator 2 0.043 0.021 329.5 <2e-16 ***
Model:Estimator 6 1.376 0.229 3551.7 <2e-16 ***
Residuals 307184 19.840 0.000
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
111 observations deleted due to missingnessrmsea.out <- cbind(omega2(fit.out),p_omega2(fit.out))
rmsea.out omega^2 partial-omega^2
ss_l1 0.0509 0.1633
ss_l2 0.0061 0.0228
icc_ov 0.0423 0.1395
icc_lv 0.0022 0.0085
Model 0.3901 0.5995
Estimator 0.0918 0.2605
ss_l1:ss_l2 0.0166 0.0598
ss_l1:icc_ov 0.0012 0.0047
ss_l1:icc_lv 0.0025 0.0094
ss_l1:Model 0.0027 0.0101
ss_l1:Estimator 0.0009 0.0035
ss_l2:icc_ov 0.0054 0.0202
ss_l2:icc_lv 0.0013 0.0051
ss_l2:Model 0.0117 0.0430
ss_l2:Estimator 0.0457 0.1491
icc_ov:icc_lv 0.0020 0.0078
icc_ov:Model 0.0173 0.0622
icc_ov:Estimator 0.0114 0.0419
icc_lv:Model 0.0189 0.0675
icc_lv:Estimator 0.0006 0.0021
Model:Estimator 0.0181 0.0648SRMRW
model <- as.formula('SRMRW ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator')
fit <- aov(model, data = sim_results)
fit.out <- summary(fit)
fit.out Df Sum Sq Mean Sq F value Pr(>F)
ss_l1 2 25.52 12.761 296166.56 <2e-16 ***
ss_l2 3 26.41 8.804 204332.83 <2e-16 ***
icc_ov 2 2.50 1.248 28955.46 <2e-16 ***
icc_lv 1 0.58 0.579 13432.28 <2e-16 ***
Model 3 44.23 14.745 342204.95 <2e-16 ***
Estimator 2 10.80 5.399 125296.55 <2e-16 ***
ss_l1:ss_l2 6 5.19 0.864 20057.33 <2e-16 ***
ss_l1:icc_ov 4 0.01 0.002 34.94 <2e-16 ***
ss_l1:icc_lv 2 0.07 0.035 812.79 <2e-16 ***
ss_l1:Model 6 1.69 0.281 6530.42 <2e-16 ***
ss_l1:Estimator 4 0.20 0.050 1156.99 <2e-16 ***
ss_l2:icc_ov 6 0.13 0.022 509.02 <2e-16 ***
ss_l2:icc_lv 3 0.09 0.031 724.90 <2e-16 ***
ss_l2:Model 9 1.42 0.158 3673.60 <2e-16 ***
ss_l2:Estimator 6 1.05 0.175 4066.67 <2e-16 ***
icc_ov:icc_lv 2 0.02 0.009 204.43 <2e-16 ***
icc_ov:Model 6 0.08 0.013 310.70 <2e-16 ***
icc_ov:Estimator 4 1.23 0.308 7153.27 <2e-16 ***
icc_lv:Model 3 0.23 0.075 1749.61 <2e-16 ***
icc_lv:Estimator 2 1.60 0.802 18624.61 <2e-16 ***
Model:Estimator 6 0.36 0.059 1380.92 <2e-16 ***
Residuals 307184 13.24 0.000
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
111 observations deleted due to missingnesssrmrw.out <- cbind(omega2(fit.out),p_omega2(fit.out))
srmrw.out omega^2 partial-omega^2
ss_l1 0.1868 0.6584
ss_l2 0.1933 0.6661
icc_ov 0.0183 0.1586
icc_lv 0.0042 0.0419
Model 0.3237 0.7696
Estimator 0.0790 0.4492
ss_l1:ss_l2 0.0379 0.2814
ss_l1:icc_ov 0.0000 0.0004
ss_l1:icc_lv 0.0005 0.0053
ss_l1:Model 0.0124 0.1131
ss_l1:Estimator 0.0015 0.0148
ss_l2:icc_ov 0.0010 0.0098
ss_l2:icc_lv 0.0007 0.0070
ss_l2:Model 0.0104 0.0971
ss_l2:Estimator 0.0077 0.0736
icc_ov:icc_lv 0.0001 0.0013
icc_ov:Model 0.0006 0.0060
icc_ov:Estimator 0.0090 0.0852
icc_lv:Model 0.0017 0.0168
icc_lv:Estimator 0.0117 0.1081
Model:Estimator 0.0026 0.0262SRMRB
model <- as.formula('SRMRB ~ ss_l1 + ss_l2 + icc_ov + icc_lv + Model + Estimator + ss_l1:ss_l2 + ss_l1:icc_ov + ss_l1:icc_lv + ss_l1:Model + ss_l1:Estimator + ss_l2:icc_ov + ss_l2:icc_lv + ss_l2:Model + ss_l2:Estimator + icc_ov:icc_lv + icc_ov:Model + icc_ov:Estimator + icc_lv:Model + icc_lv:Estimator + Model:Estimator')
fit <- aov(model, data = sim_results)
fit.out <- summary(fit)
fit.out Df Sum Sq Mean Sq F value Pr(>F)
ss_l1 2 44.99 22.49 33620.78 < 2e-16 ***
ss_l2 3 284.76 94.92 141877.12 < 2e-16 ***
icc_ov 2 117.74 58.87 87995.72 < 2e-16 ***
icc_lv 1 32.82 32.82 49050.45 < 2e-16 ***
Model 3 17.37 5.79 8656.17 < 2e-16 ***
Estimator 2 48.54 24.27 36276.51 < 2e-16 ***
ss_l1:ss_l2 6 4.86 0.81 1211.68 < 2e-16 ***
ss_l1:icc_ov 4 33.56 8.39 12540.25 < 2e-16 ***
ss_l1:icc_lv 2 9.23 4.61 6898.00 < 2e-16 ***
ss_l1:Model 6 0.40 0.07 99.89 < 2e-16 ***
ss_l1:Estimator 4 0.04 0.01 14.14 1.52e-11 ***
ss_l2:icc_ov 6 3.69 0.61 918.94 < 2e-16 ***
ss_l2:icc_lv 3 12.77 4.26 6364.08 < 2e-16 ***
ss_l2:Model 9 0.99 0.11 164.53 < 2e-16 ***
ss_l2:Estimator 6 2.02 0.34 503.67 < 2e-16 ***
icc_ov:icc_lv 2 27.31 13.66 20412.65 < 2e-16 ***
icc_ov:Model 6 4.91 0.82 1223.78 < 2e-16 ***
icc_ov:Estimator 4 0.25 0.06 91.96 < 2e-16 ***
icc_lv:Model 3 10.77 3.59 5366.68 < 2e-16 ***
icc_lv:Estimator 2 1.76 0.88 1315.58 < 2e-16 ***
Model:Estimator 6 0.82 0.14 204.37 < 2e-16 ***
Residuals 307184 205.51 0.00
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
111 observations deleted due to missingnesssrmrb.out <- cbind(omega2(fit.out),p_omega2(fit.out))
srmrb.out omega^2 partial-omega^2
ss_l1 0.0520 0.1795
ss_l2 0.3292 0.5807
icc_ov 0.1361 0.3642
icc_lv 0.0379 0.1377
Model 0.0201 0.0779
Estimator 0.0561 0.1910
ss_l1:ss_l2 0.0056 0.0231
ss_l1:icc_ov 0.0388 0.1403
ss_l1:icc_lv 0.0107 0.0430
ss_l1:Model 0.0005 0.0019
ss_l1:Estimator 0.0000 0.0002
ss_l2:icc_ov 0.0043 0.0176
ss_l2:icc_lv 0.0148 0.0585
ss_l2:Model 0.0011 0.0048
ss_l2:Estimator 0.0023 0.0097
icc_ov:icc_lv 0.0316 0.1173
icc_ov:Model 0.0057 0.0233
icc_ov:Estimator 0.0003 0.0012
icc_lv:Model 0.0124 0.0498
icc_lv:Estimator 0.0020 0.0085
Model:Estimator 0.0009 0.0040Summary Table of Effect Sizes
tb <- cbind(cfi.out, tli.out, rmsea.out, srmrw.out, srmrb.out)
kable(tb, format='html') %>%
kable_styling(full_width = T) %>%
add_header_above(c('Effect'=1,'CFI'=2,'TLI'=2,'RMSEA'=2,'SRMRW'=2,'SRMRB'=2))| omega^2 | partial-omega^2 | omega^2 | partial-omega^2 | omega^2 | partial-omega^2 | omega^2 | partial-omega^2 | omega^2 | partial-omega^2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| ss_l1 | 0.0402 | 0.0835 | 0.0404 | 0.0839 | 0.0509 | 0.1633 | 0.1868 | 0.6584 | 0.0520 | 0.1795 |
| ss_l2 | 0.0129 | 0.0285 | 0.0130 | 0.0287 | 0.0061 | 0.0228 | 0.1933 | 0.6661 | 0.3292 | 0.5807 |
| icc_ov | 0.0050 | 0.0112 | 0.0050 | 0.0111 | 0.0423 | 0.1395 | 0.0183 | 0.1586 | 0.1361 | 0.3642 |
| icc_lv | 0.0043 | 0.0097 | 0.0044 | 0.0098 | 0.0022 | 0.0085 | 0.0042 | 0.0419 | 0.0379 | 0.1377 |
| Model | 0.3173 | 0.4184 | 0.3153 | 0.4166 | 0.3901 | 0.5995 | 0.3237 | 0.7696 | 0.0201 | 0.0779 |
| Estimator | 0.0236 | 0.0507 | 0.0237 | 0.0508 | 0.0918 | 0.2605 | 0.0790 | 0.4492 | 0.0561 | 0.1910 |
| ss_l1:ss_l2 | 0.0362 | 0.0758 | 0.0364 | 0.0762 | 0.0166 | 0.0598 | 0.0379 | 0.2814 | 0.0056 | 0.0231 |
| ss_l1:icc_ov | 0.0047 | 0.0105 | 0.0047 | 0.0106 | 0.0012 | 0.0047 | 0.0000 | 0.0004 | 0.0388 | 0.1403 |
| ss_l1:icc_lv | 0.0005 | 0.0011 | 0.0005 | 0.0011 | 0.0025 | 0.0094 | 0.0005 | 0.0053 | 0.0107 | 0.0430 |
| ss_l1:Model | 0.0010 | 0.0023 | 0.0010 | 0.0022 | 0.0027 | 0.0101 | 0.0124 | 0.1131 | 0.0005 | 0.0019 |
| ss_l1:Estimator | 0.0016 | 0.0036 | 0.0016 | 0.0036 | 0.0009 | 0.0035 | 0.0015 | 0.0148 | 0.0000 | 0.0002 |
| ss_l2:icc_ov | 0.0014 | 0.0031 | 0.0013 | 0.0030 | 0.0054 | 0.0202 | 0.0010 | 0.0098 | 0.0043 | 0.0176 |
| ss_l2:icc_lv | 0.0055 | 0.0124 | 0.0056 | 0.0125 | 0.0013 | 0.0051 | 0.0007 | 0.0070 | 0.0148 | 0.0585 |
| ss_l2:Model | 0.0031 | 0.0069 | 0.0032 | 0.0071 | 0.0117 | 0.0430 | 0.0104 | 0.0971 | 0.0011 | 0.0048 |
| ss_l2:Estimator | 0.0340 | 0.0716 | 0.0342 | 0.0719 | 0.0457 | 0.1491 | 0.0077 | 0.0736 | 0.0023 | 0.0097 |
| icc_ov:icc_lv | 0.0031 | 0.0069 | 0.0031 | 0.0070 | 0.0020 | 0.0078 | 0.0001 | 0.0013 | 0.0316 | 0.1173 |
| icc_ov:Model | 0.0070 | 0.0157 | 0.0070 | 0.0157 | 0.0173 | 0.0622 | 0.0006 | 0.0060 | 0.0057 | 0.0233 |
| icc_ov:Estimator | 0.0062 | 0.0139 | 0.0063 | 0.0140 | 0.0114 | 0.0419 | 0.0090 | 0.0852 | 0.0003 | 0.0012 |
| icc_lv:Model | 0.0181 | 0.0395 | 0.0184 | 0.0400 | 0.0189 | 0.0675 | 0.0017 | 0.0168 | 0.0124 | 0.0498 |
| icc_lv:Estimator | 0.0132 | 0.0290 | 0.0133 | 0.0292 | 0.0006 | 0.0021 | 0.0117 | 0.1081 | 0.0020 | 0.0085 |
| Model:Estimator | 0.0199 | 0.0431 | 0.0200 | 0.0433 | 0.0181 | 0.0648 | 0.0026 | 0.0262 | 0.0009 | 0.0040 |
## Print out in tex
print(xtable(tb, digits = 3), booktabs = T, include.rownames = T)% latex table generated in R 3.5.2 by xtable 1.8-3 package
% Fri May 17 17:03:55 2019
\begin{table}[ht]
\centering
\begin{tabular}{rrrrrrrrrrr}
\toprule
& omega\verb|^|2 & partial-omega\verb|^|2 & omega\verb|^|2 & partial-omega\verb|^|2 & omega\verb|^|2 & partial-omega\verb|^|2 & omega\verb|^|2 & partial-omega\verb|^|2 & omega\verb|^|2 & partial-omega\verb|^|2 \\
\midrule
ss\_l1 & 0.040 & 0.084 & 0.040 & 0.084 & 0.051 & 0.163 & 0.187 & 0.658 & 0.052 & 0.179 \\
ss\_l2 & 0.013 & 0.028 & 0.013 & 0.029 & 0.006 & 0.023 & 0.193 & 0.666 & 0.329 & 0.581 \\
icc\_ov & 0.005 & 0.011 & 0.005 & 0.011 & 0.042 & 0.140 & 0.018 & 0.159 & 0.136 & 0.364 \\
icc\_lv & 0.004 & 0.010 & 0.004 & 0.010 & 0.002 & 0.008 & 0.004 & 0.042 & 0.038 & 0.138 \\
Model & 0.317 & 0.418 & 0.315 & 0.417 & 0.390 & 0.600 & 0.324 & 0.770 & 0.020 & 0.078 \\
Estimator & 0.024 & 0.051 & 0.024 & 0.051 & 0.092 & 0.261 & 0.079 & 0.449 & 0.056 & 0.191 \\
ss\_l1:ss\_l2 & 0.036 & 0.076 & 0.036 & 0.076 & 0.017 & 0.060 & 0.038 & 0.281 & 0.006 & 0.023 \\
ss\_l1:icc\_ov & 0.005 & 0.010 & 0.005 & 0.011 & 0.001 & 0.005 & 0.000 & 0.000 & 0.039 & 0.140 \\
ss\_l1:icc\_lv & 0.000 & 0.001 & 0.000 & 0.001 & 0.002 & 0.009 & 0.000 & 0.005 & 0.011 & 0.043 \\
ss\_l1:Model & 0.001 & 0.002 & 0.001 & 0.002 & 0.003 & 0.010 & 0.012 & 0.113 & 0.000 & 0.002 \\
ss\_l1:Estimator & 0.002 & 0.004 & 0.002 & 0.004 & 0.001 & 0.004 & 0.002 & 0.015 & 0.000 & 0.000 \\
ss\_l2:icc\_ov & 0.001 & 0.003 & 0.001 & 0.003 & 0.005 & 0.020 & 0.001 & 0.010 & 0.004 & 0.018 \\
ss\_l2:icc\_lv & 0.005 & 0.012 & 0.006 & 0.012 & 0.001 & 0.005 & 0.001 & 0.007 & 0.015 & 0.058 \\
ss\_l2:Model & 0.003 & 0.007 & 0.003 & 0.007 & 0.012 & 0.043 & 0.010 & 0.097 & 0.001 & 0.005 \\
ss\_l2:Estimator & 0.034 & 0.072 & 0.034 & 0.072 & 0.046 & 0.149 & 0.008 & 0.074 & 0.002 & 0.010 \\
icc\_ov:icc\_lv & 0.003 & 0.007 & 0.003 & 0.007 & 0.002 & 0.008 & 0.000 & 0.001 & 0.032 & 0.117 \\
icc\_ov:Model & 0.007 & 0.016 & 0.007 & 0.016 & 0.017 & 0.062 & 0.001 & 0.006 & 0.006 & 0.023 \\
icc\_ov:Estimator & 0.006 & 0.014 & 0.006 & 0.014 & 0.011 & 0.042 & 0.009 & 0.085 & 0.000 & 0.001 \\
icc\_lv:Model & 0.018 & 0.040 & 0.018 & 0.040 & 0.019 & 0.068 & 0.002 & 0.017 & 0.012 & 0.050 \\
icc\_lv:Estimator & 0.013 & 0.029 & 0.013 & 0.029 & 0.001 & 0.002 & 0.012 & 0.108 & 0.002 & 0.008 \\
Model:Estimator & 0.020 & 0.043 & 0.020 & 0.043 & 0.018 & 0.065 & 0.003 & 0.026 & 0.001 & 0.004 \\
\bottomrule
\end{tabular}
\end{table}## Table of partial-omega2
tb <- cbind(cfi.out[,2, drop=F], tli.out[,2, drop=F], rmsea.out[,2, drop=F], srmrw.out[,2, drop=F], srmrb.out[,2, drop=F])
kable(tb, format='html') %>%
kable_styling(full_width = T) %>%
add_header_above(c('Effect'=1,'CFI'=1,'TLI'=1,'RMSEA'=1,'SRMRW'=1,'SRMRB'=1))| partial-omega^2 | partial-omega^2 | partial-omega^2 | partial-omega^2 | partial-omega^2 | |
|---|---|---|---|---|---|
| ss_l1 | 0.0835 | 0.0839 | 0.1633 | 0.6584 | 0.1795 |
| ss_l2 | 0.0285 | 0.0287 | 0.0228 | 0.6661 | 0.5807 |
| icc_ov | 0.0112 | 0.0111 | 0.1395 | 0.1586 | 0.3642 |
| icc_lv | 0.0097 | 0.0098 | 0.0085 | 0.0419 | 0.1377 |
| Model | 0.4184 | 0.4166 | 0.5995 | 0.7696 | 0.0779 |
| Estimator | 0.0507 | 0.0508 | 0.2605 | 0.4492 | 0.1910 |
| ss_l1:ss_l2 | 0.0758 | 0.0762 | 0.0598 | 0.2814 | 0.0231 |
| ss_l1:icc_ov | 0.0105 | 0.0106 | 0.0047 | 0.0004 | 0.1403 |
| ss_l1:icc_lv | 0.0011 | 0.0011 | 0.0094 | 0.0053 | 0.0430 |
| ss_l1:Model | 0.0023 | 0.0022 | 0.0101 | 0.1131 | 0.0019 |
| ss_l1:Estimator | 0.0036 | 0.0036 | 0.0035 | 0.0148 | 0.0002 |
| ss_l2:icc_ov | 0.0031 | 0.0030 | 0.0202 | 0.0098 | 0.0176 |
| ss_l2:icc_lv | 0.0124 | 0.0125 | 0.0051 | 0.0070 | 0.0585 |
| ss_l2:Model | 0.0069 | 0.0071 | 0.0430 | 0.0971 | 0.0048 |
| ss_l2:Estimator | 0.0716 | 0.0719 | 0.1491 | 0.0736 | 0.0097 |
| icc_ov:icc_lv | 0.0069 | 0.0070 | 0.0078 | 0.0013 | 0.1173 |
| icc_ov:Model | 0.0157 | 0.0157 | 0.0622 | 0.0060 | 0.0233 |
| icc_ov:Estimator | 0.0139 | 0.0140 | 0.0419 | 0.0852 | 0.0012 |
| icc_lv:Model | 0.0395 | 0.0400 | 0.0675 | 0.0168 | 0.0498 |
| icc_lv:Estimator | 0.0290 | 0.0292 | 0.0021 | 0.1081 | 0.0085 |
| Model:Estimator | 0.0431 | 0.0433 | 0.0648 | 0.0262 | 0.0040 |
## Print out in tex
print(xtable(tb, digits = 3), booktabs = T, include.rownames = T)% latex table generated in R 3.5.2 by xtable 1.8-3 package
% Fri May 17 17:03:55 2019
\begin{table}[ht]
\centering
\begin{tabular}{rrrrrr}
\toprule
& partial-omega\verb|^|2 & partial-omega\verb|^|2 & partial-omega\verb|^|2 & partial-omega\verb|^|2 & partial-omega\verb|^|2 \\
\midrule
ss\_l1 & 0.084 & 0.084 & 0.163 & 0.658 & 0.179 \\
ss\_l2 & 0.028 & 0.029 & 0.023 & 0.666 & 0.581 \\
icc\_ov & 0.011 & 0.011 & 0.140 & 0.159 & 0.364 \\
icc\_lv & 0.010 & 0.010 & 0.008 & 0.042 & 0.138 \\
Model & 0.418 & 0.417 & 0.600 & 0.770 & 0.078 \\
Estimator & 0.051 & 0.051 & 0.261 & 0.449 & 0.191 \\
ss\_l1:ss\_l2 & 0.076 & 0.076 & 0.060 & 0.281 & 0.023 \\
ss\_l1:icc\_ov & 0.010 & 0.011 & 0.005 & 0.000 & 0.140 \\
ss\_l1:icc\_lv & 0.001 & 0.001 & 0.009 & 0.005 & 0.043 \\
ss\_l1:Model & 0.002 & 0.002 & 0.010 & 0.113 & 0.002 \\
ss\_l1:Estimator & 0.004 & 0.004 & 0.004 & 0.015 & 0.000 \\
ss\_l2:icc\_ov & 0.003 & 0.003 & 0.020 & 0.010 & 0.018 \\
ss\_l2:icc\_lv & 0.012 & 0.012 & 0.005 & 0.007 & 0.058 \\
ss\_l2:Model & 0.007 & 0.007 & 0.043 & 0.097 & 0.005 \\
ss\_l2:Estimator & 0.072 & 0.072 & 0.149 & 0.074 & 0.010 \\
icc\_ov:icc\_lv & 0.007 & 0.007 & 0.008 & 0.001 & 0.117 \\
icc\_ov:Model & 0.016 & 0.016 & 0.062 & 0.006 & 0.023 \\
icc\_ov:Estimator & 0.014 & 0.014 & 0.042 & 0.085 & 0.001 \\
icc\_lv:Model & 0.040 & 0.040 & 0.068 & 0.017 & 0.050 \\
icc\_lv:Estimator & 0.029 & 0.029 & 0.002 & 0.108 & 0.008 \\
Model:Estimator & 0.043 & 0.043 & 0.065 & 0.026 & 0.004 \\
\bottomrule
\end{tabular}
\end{table}## Table of omege-2
tb <- cbind(cfi.out[,1, drop=F], tli.out[,1, drop=F], rmsea.out[,1, drop=F], srmrw.out[,1, drop=F], srmrb.out[,1, drop=F])
kable(tb, format='html') %>%
kable_styling(full_width = T) %>%
add_header_above(c('Effect'=1,'CFI'=1,'TLI'=1,'RMSEA'=1,'SRMRW'=1,'SRMRB'=1))| omega^2 | omega^2 | omega^2 | omega^2 | omega^2 | |
|---|---|---|---|---|---|
| ss_l1 | 0.0402 | 0.0404 | 0.0509 | 0.1868 | 0.0520 |
| ss_l2 | 0.0129 | 0.0130 | 0.0061 | 0.1933 | 0.3292 |
| icc_ov | 0.0050 | 0.0050 | 0.0423 | 0.0183 | 0.1361 |
| icc_lv | 0.0043 | 0.0044 | 0.0022 | 0.0042 | 0.0379 |
| Model | 0.3173 | 0.3153 | 0.3901 | 0.3237 | 0.0201 |
| Estimator | 0.0236 | 0.0237 | 0.0918 | 0.0790 | 0.0561 |
| ss_l1:ss_l2 | 0.0362 | 0.0364 | 0.0166 | 0.0379 | 0.0056 |
| ss_l1:icc_ov | 0.0047 | 0.0047 | 0.0012 | 0.0000 | 0.0388 |
| ss_l1:icc_lv | 0.0005 | 0.0005 | 0.0025 | 0.0005 | 0.0107 |
| ss_l1:Model | 0.0010 | 0.0010 | 0.0027 | 0.0124 | 0.0005 |
| ss_l1:Estimator | 0.0016 | 0.0016 | 0.0009 | 0.0015 | 0.0000 |
| ss_l2:icc_ov | 0.0014 | 0.0013 | 0.0054 | 0.0010 | 0.0043 |
| ss_l2:icc_lv | 0.0055 | 0.0056 | 0.0013 | 0.0007 | 0.0148 |
| ss_l2:Model | 0.0031 | 0.0032 | 0.0117 | 0.0104 | 0.0011 |
| ss_l2:Estimator | 0.0340 | 0.0342 | 0.0457 | 0.0077 | 0.0023 |
| icc_ov:icc_lv | 0.0031 | 0.0031 | 0.0020 | 0.0001 | 0.0316 |
| icc_ov:Model | 0.0070 | 0.0070 | 0.0173 | 0.0006 | 0.0057 |
| icc_ov:Estimator | 0.0062 | 0.0063 | 0.0114 | 0.0090 | 0.0003 |
| icc_lv:Model | 0.0181 | 0.0184 | 0.0189 | 0.0017 | 0.0124 |
| icc_lv:Estimator | 0.0132 | 0.0133 | 0.0006 | 0.0117 | 0.0020 |
| Model:Estimator | 0.0199 | 0.0200 | 0.0181 | 0.0026 | 0.0009 |
## Print out in tex
print(xtable(tb, digits = 3), booktabs = T, include.rownames = T)% latex table generated in R 3.5.2 by xtable 1.8-3 package
% Fri May 17 17:03:55 2019
\begin{table}[ht]
\centering
\begin{tabular}{rrrrrr}
\toprule
& omega\verb|^|2 & omega\verb|^|2 & omega\verb|^|2 & omega\verb|^|2 & omega\verb|^|2 \\
\midrule
ss\_l1 & 0.040 & 0.040 & 0.051 & 0.187 & 0.052 \\
ss\_l2 & 0.013 & 0.013 & 0.006 & 0.193 & 0.329 \\
icc\_ov & 0.005 & 0.005 & 0.042 & 0.018 & 0.136 \\
icc\_lv & 0.004 & 0.004 & 0.002 & 0.004 & 0.038 \\
Model & 0.317 & 0.315 & 0.390 & 0.324 & 0.020 \\
Estimator & 0.024 & 0.024 & 0.092 & 0.079 & 0.056 \\
ss\_l1:ss\_l2 & 0.036 & 0.036 & 0.017 & 0.038 & 0.006 \\
ss\_l1:icc\_ov & 0.005 & 0.005 & 0.001 & 0.000 & 0.039 \\
ss\_l1:icc\_lv & 0.000 & 0.000 & 0.002 & 0.000 & 0.011 \\
ss\_l1:Model & 0.001 & 0.001 & 0.003 & 0.012 & 0.000 \\
ss\_l1:Estimator & 0.002 & 0.002 & 0.001 & 0.002 & 0.000 \\
ss\_l2:icc\_ov & 0.001 & 0.001 & 0.005 & 0.001 & 0.004 \\
ss\_l2:icc\_lv & 0.005 & 0.006 & 0.001 & 0.001 & 0.015 \\
ss\_l2:Model & 0.003 & 0.003 & 0.012 & 0.010 & 0.001 \\
ss\_l2:Estimator & 0.034 & 0.034 & 0.046 & 0.008 & 0.002 \\
icc\_ov:icc\_lv & 0.003 & 0.003 & 0.002 & 0.000 & 0.032 \\
icc\_ov:Model & 0.007 & 0.007 & 0.017 & 0.001 & 0.006 \\
icc\_ov:Estimator & 0.006 & 0.006 & 0.011 & 0.009 & 0.000 \\
icc\_lv:Model & 0.018 & 0.018 & 0.019 & 0.002 & 0.012 \\
icc\_lv:Estimator & 0.013 & 0.013 & 0.001 & 0.012 & 0.002 \\
Model:Estimator & 0.020 & 0.020 & 0.018 & 0.003 & 0.001 \\
\bottomrule
\end{tabular}
\end{table}
sessionInfo()R version 3.5.2 (2018-12-20)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 17134)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252
[2] LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] xtable_1.8-3 kableExtra_1.0.1 psych_1.8.12 car_3.0-2
[5] carData_3.0-2 forcats_0.3.0 stringr_1.3.1 dplyr_0.8.0.1
[9] purrr_0.2.5 readr_1.3.1 tidyr_0.8.2 tibble_2.0.1
[13] ggplot2_3.1.0 tidyverse_1.2.1
loaded via a namespace (and not attached):
[1] Rcpp_1.0.0 lubridate_1.7.4 lattice_0.20-38
[4] assertthat_0.2.0 rprojroot_1.3-2 digest_0.6.18
[7] R6_2.3.0 cellranger_1.1.0 plyr_1.8.4
[10] backports_1.1.3 evaluate_0.12 highr_0.7
[13] httr_1.4.0 pillar_1.3.1 rlang_0.3.1
[16] lazyeval_0.2.1 curl_3.3 readxl_1.2.0
[19] rstudioapi_0.9.0 data.table_1.12.0 whisker_0.3-2
[22] rmarkdown_1.11 labeling_0.3 webshot_0.5.1
[25] foreign_0.8-71 munsell_0.5.0 broom_0.5.1
[28] compiler_3.5.2 modelr_0.1.2 xfun_0.4
[31] pkgconfig_2.0.2 mnormt_1.5-5 htmltools_0.3.6
[34] tidyselect_0.2.5 workflowr_1.3.0 rio_0.5.16
[37] viridisLite_0.3.0 crayon_1.3.4 withr_2.1.2
[40] grid_3.5.2 nlme_3.1-137 jsonlite_1.6
[43] gtable_0.2.0 git2r_0.24.0 magrittr_1.5
[46] formatR_1.5 scales_1.0.0 zip_1.0.0
[49] cli_1.0.1 stringi_1.2.4 fs_1.2.6
[52] xml2_1.2.0 generics_0.0.2 openxlsx_4.1.0
[55] tools_3.5.2 glue_1.3.0 hms_0.4.2
[58] abind_1.4-5 parallel_3.5.2 yaml_2.2.0
[61] colorspace_1.4-0 rvest_0.3.2 knitr_1.21
[64] haven_2.0.0